
《深度学习》章五 RNN 第2节 NLP & Word Embeddings
章五 RNN 第2节 NLP & Word Embeddings
第2节 NLP & Word Embeddings
2.1 单词表示
one-hot表征单词的方法最大的缺点就是每个单词都是独立的、正交的,无法知道不同单词之间的相似程度。例如Apple和Orange都是水果,词性相近,但是单从one-hot编码上来看,内积为零,无法知道二者的相似性。在NLP中,我们更希望能掌握不同单词之间的相似程度。
因此,我们可以使用特征表征(Featurized representation)的方法对每个单词进行编码。也就是使用一个特征向量表征单词,特征向量的每个元素都是对该单词某一特征的量化描述,量化范围可以是[-1,1]之间。
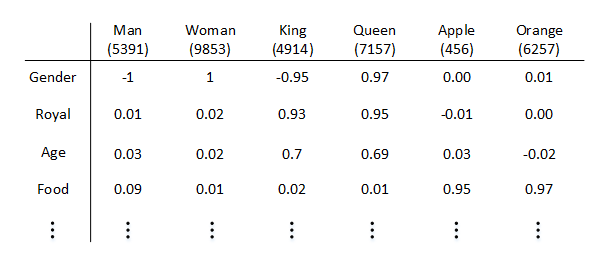
特征向量的长度依情况而定,特征元素越多则对单词表征得越全面。这里的特征向量长度设定为300。使用特征表征之后,词汇表中的每个单词都可以使用对应的300 x 1的向量来表示,该向量的每个元素表示该单词对应的某个特征值。每个单词用e+词汇表索引的方式标记
这种特征表征的优点是根据特征向量能清晰知道不同单词之间的相似程度,例如Apple和Orange之间的相似度较高,很可能属于同一类别。这种单词“类别”化的方式,大大提高了有限词汇量的泛化能力。这种特征化单词的操作被称为Word Embeddings,即单词嵌入。
值得一提的是,这里特征向量的每个特征元素含义是具体的,对应到实际特征,例如性别、年龄等。而在实际应用中,特征向量很多特征元素并不一定对应到有物理意义的特征,是比较抽象的。但是,这并不影响对每个单词的有效表征,同样能比较不同单词之间的相似性。
2.2 使用词嵌入
featurized representation的优点是可以减少训练样本的数目,前提是对海量单词建立特征向量表述(word embedding)。这样,即使训练样本不够多,测试时遇到陌生单词,例如“durian cultivator”,根据之前海量词汇特征向量就判断出“durian”也是一种水果,与“apple”类似,而“cultivator”与“farmer”也很相似。
通过 word embedding 得到特征向量,
这样遇到训练过程没有的样本时,由于特征向量时类似的,所以,神经网络也能得到相应的输出
featurized representation的特性使得很多NLP任务能方便地进行迁移学习。方法是:
- 从海量词汇库中学习word embeddings,即所有单词的特征向量。或者从网上下载预训练好的word embeddings。
- 使用较少的训练样本,将word embeddings迁移到新的任务中。
- (可选):继续使用新数据微调word embeddings。
人脸特征编码有很多相似性。人脸图片经过Siamese网络,得到其特征向量f(x)f(x),这点跟word embedding是类似的。二者不同的是Siamese网络输入的人脸图片可以是数据库之外的;而word embedding一般都是已建立的词汇库中的单词,非词汇库单词统一用< UNK >表示。
对于embedding的理解:大概是得到神经网络的输入的部分,也就是编码部分,获得特征部分,这一部分也是要训练的把。
2.3 Properties of word embeddings
Word embeddings可以帮助我们找到不同单词之间的相似类别关系。


2.4 Embedding matrix

2.5 Learning word embeddings
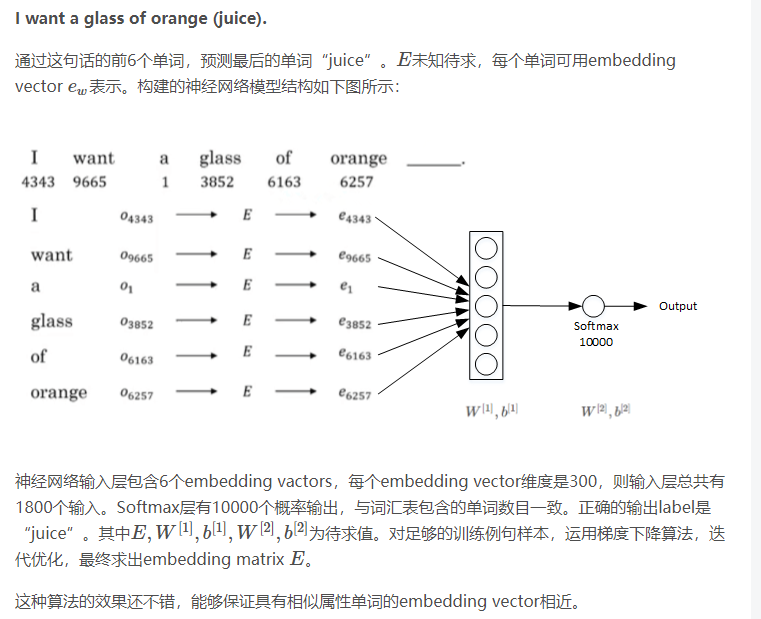
embedding matrix E可以通过构建自然语言模型,运用梯度下降算法得到。举个简单的例子,输入样本是下面这句话:

2.6 Word2Vec

还提出,softmax运算量大,用树来解决,高频词汇在顶部
Skip-Gram模型是Word2Vec的一种,Word2Vec的另外一种模型是CBOW(Continuous Bag of Words)。
2.7 Negative Sampling

把 softmax转化成了 k+1个的二分类

2.8 GloVe word vectors

2.9 Sentiment Classification
情感分类一般是根据一句话来判断其喜爱程度,例如1~5星分布。如下图所示:

情感分类问题的一个主要挑战是缺少足够多的训练样本。而Word embedding恰恰可以帮助解决训练样本不足的问题。
首先介绍使用word embedding解决情感分类问题的一个简单模型算法。
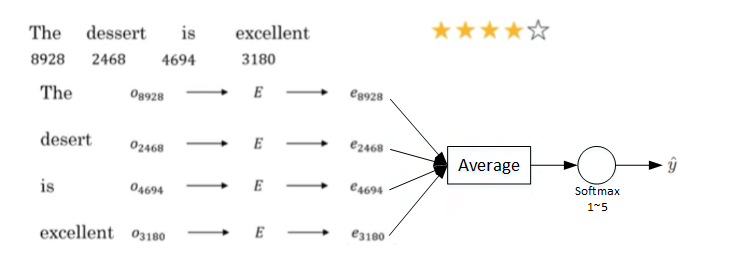
如上图所示,这句话的4个单词分别用embedding vector表示。e8928,e2468,e4694,e3180e8928,e2468,e4694,e3180计算均值,这样得到的平均向量的维度仍是300。最后经过softmax输出1~5星。这种模型结构简单,计算量不大,不论句子长度多长,都使用平均的方式得到300D的embedding vector。该模型实际表现较好。
但是,这种简单模型的缺点是使用平均方法,没有考虑句子中单词出现的次序,忽略其位置信息。而有时候,不同单词出现的次序直接决定了句意,即情感分类的结果。例如下面这句话:
Completely lacking in good taste, good service, and good ambience.
虽然这句话中包含了3个“good”,但是其前面出现了“lacking”,很明显这句话句意是negative的。如果使用上面介绍的平均算法,则很可能会错误识别为positive的,因为忽略了单词出现的次序。
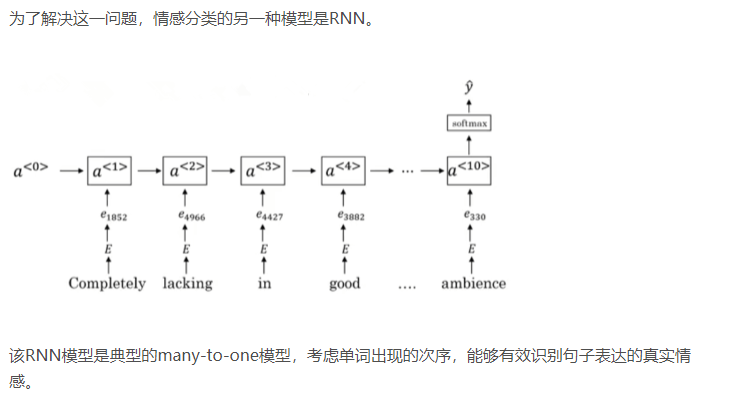
值得一提的是使用word embedding,能够有效提高模型的泛化能力,即使训练样本不多,也能保证模型有不错的性能。
2.10 Debiasing word embeddings
Word embeddings中存在一些性别、宗教、种族等偏见或者歧视。例如下面这两句话:
Man: Woman as King: Queen
Man: Computer programmer as Woman: Homemaker
Father: Doctor as Mother: Nurse
很明显,第二句话和第三句话存在性别偏见,因为Woman和Mother也可以是Computer programmer和Doctor。

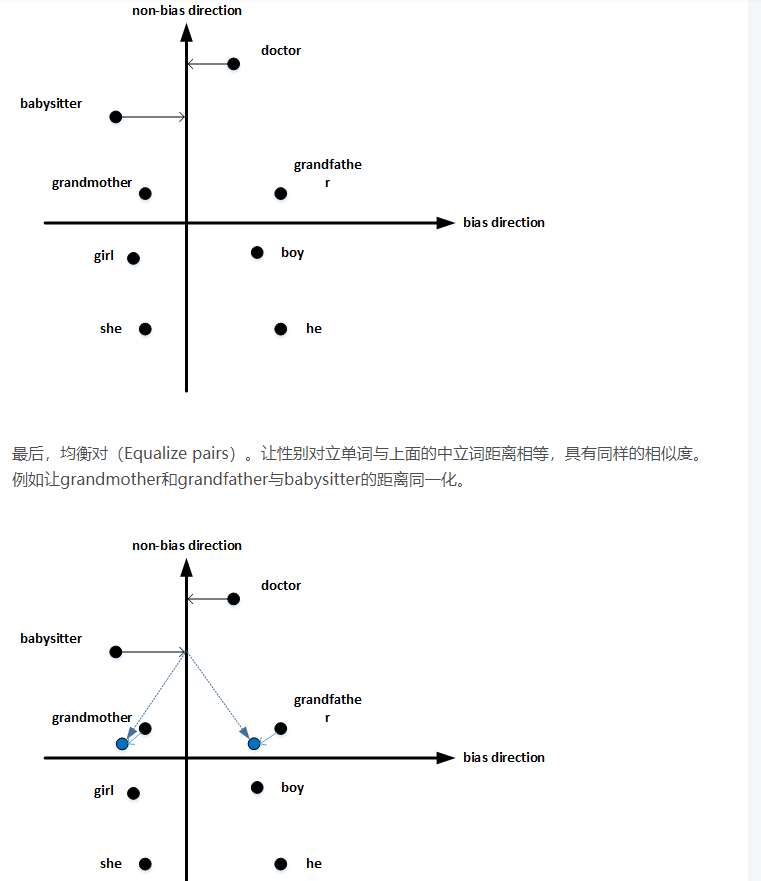
值得注意的是,掌握哪些单词需要中立化非常重要。一般来说,大部分英文单词,例如职业、身份等都需要中立化,消除embedding vector中性别这一维度的影响。
