《深度学习》 章五 RNN 第1节 RNN
章五 RNN 第1节 RNN
第1节 RNN
1.1 什么是序列模型
序列模型能够应用在许多领域,例如:
- 语音识别
- 音乐发生器
- 情感分类
- DNA序列分析
- 机器翻译
- 视频动作识别
- 命名实体识别
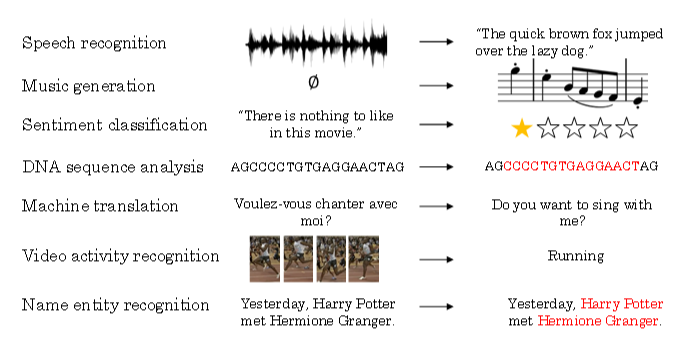
这些序列模型基本都属于监督式学习,输入x和输出y不一定都是序列模型。如果都是序列模型的话,模型长度不一定完全一致。
1.2 数学符号
Harry Potter and Hermione Granger invented a new spell.
该句话包含9个单词,输出y即为1 x 9向量,每位表征对应单词是否为人名的一部分,1表示是,0表示否。



1.3 循环神经网络模型
对于序列模型,如果使用标准的神经网络,其模型结构如下:
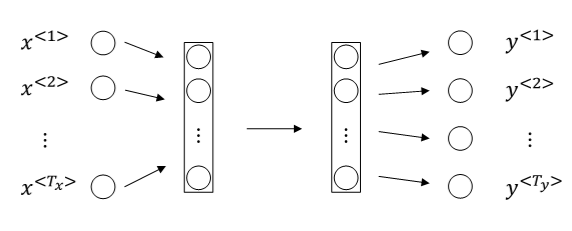
使用标准的神经网络模型存在两个问题:
第一个问题,不同样本的输入序列长度或输出序列长度不同。造成模型难以统一。解决办法之一是设定一个最大序列长度,对每个输入和输出序列补零并统一到最大长度。但是这种做法实际效果并不理想。
第二个问题,也是主要问题,这种标准神经网络结构无法共享序列不同x
前向传播
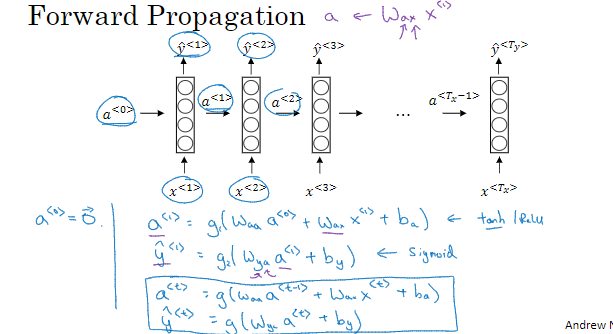
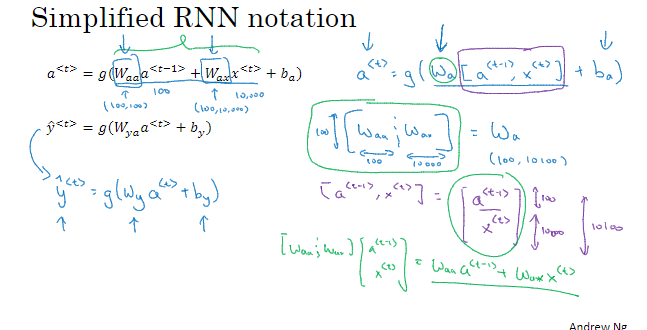
简化RNN计算过程
另外还有双向RNN,即BRNN

1.4 通过实践的反向传播

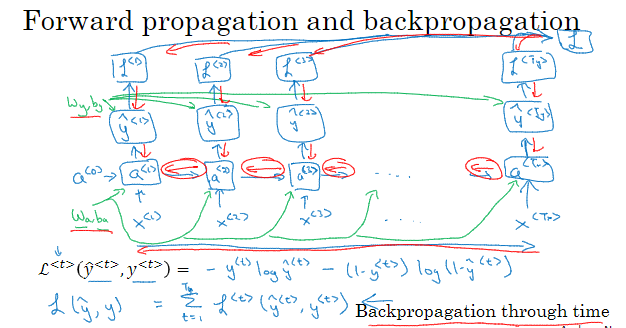
1.5 更多不同类型的RNNs
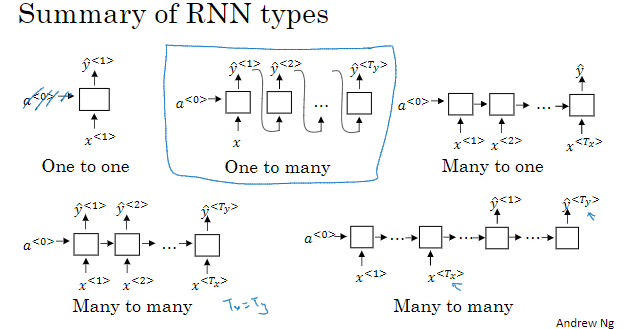
1.6 语言模型与序列生成

其实下面这些没有看懂,不知道为什么没有输出就能推测出一个句子,或者是生成一个句子了
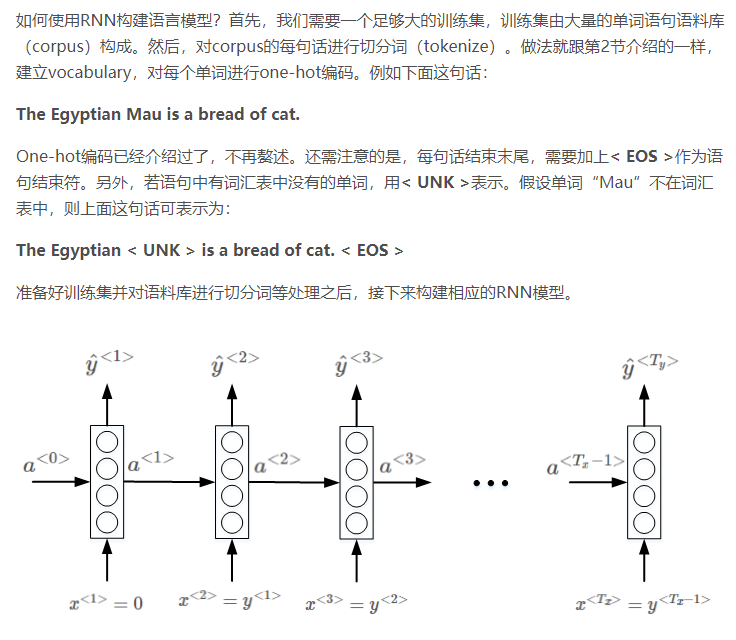
其实也就是个条件概率,前面推测后面的概率

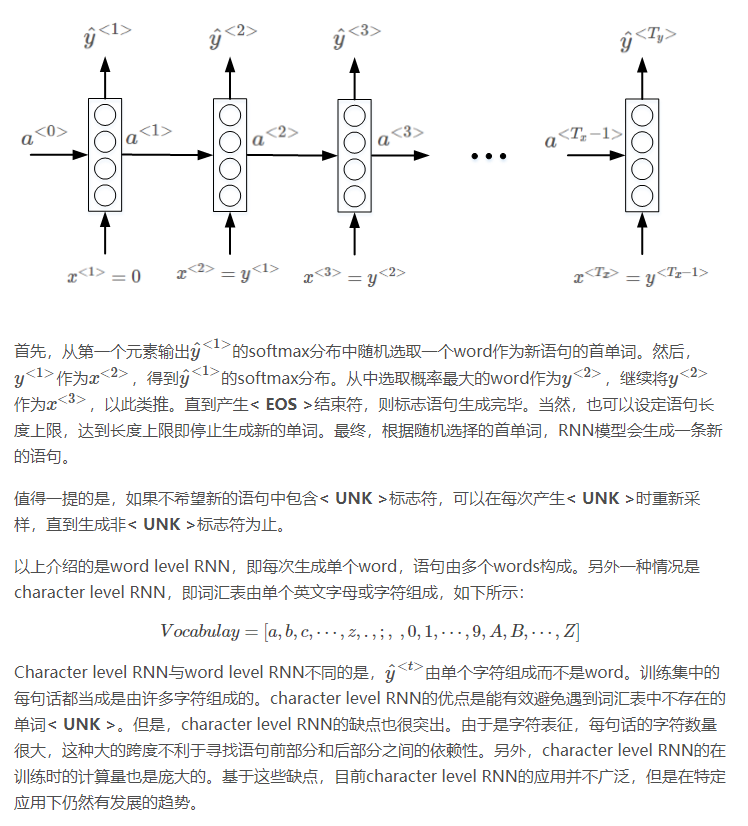
1.7 对新序列采样
训练好模型之后,进行新的序列采样,产生新的语句。(这一节介绍了,随机采样获得新序列以及字符模型)
1.8 带有神经网络的梯度消失
梯度消失与梯度爆炸(设置阈值,缩小)问题

1.9 Gated Recurrent Unit(GRU)
简化版GRU
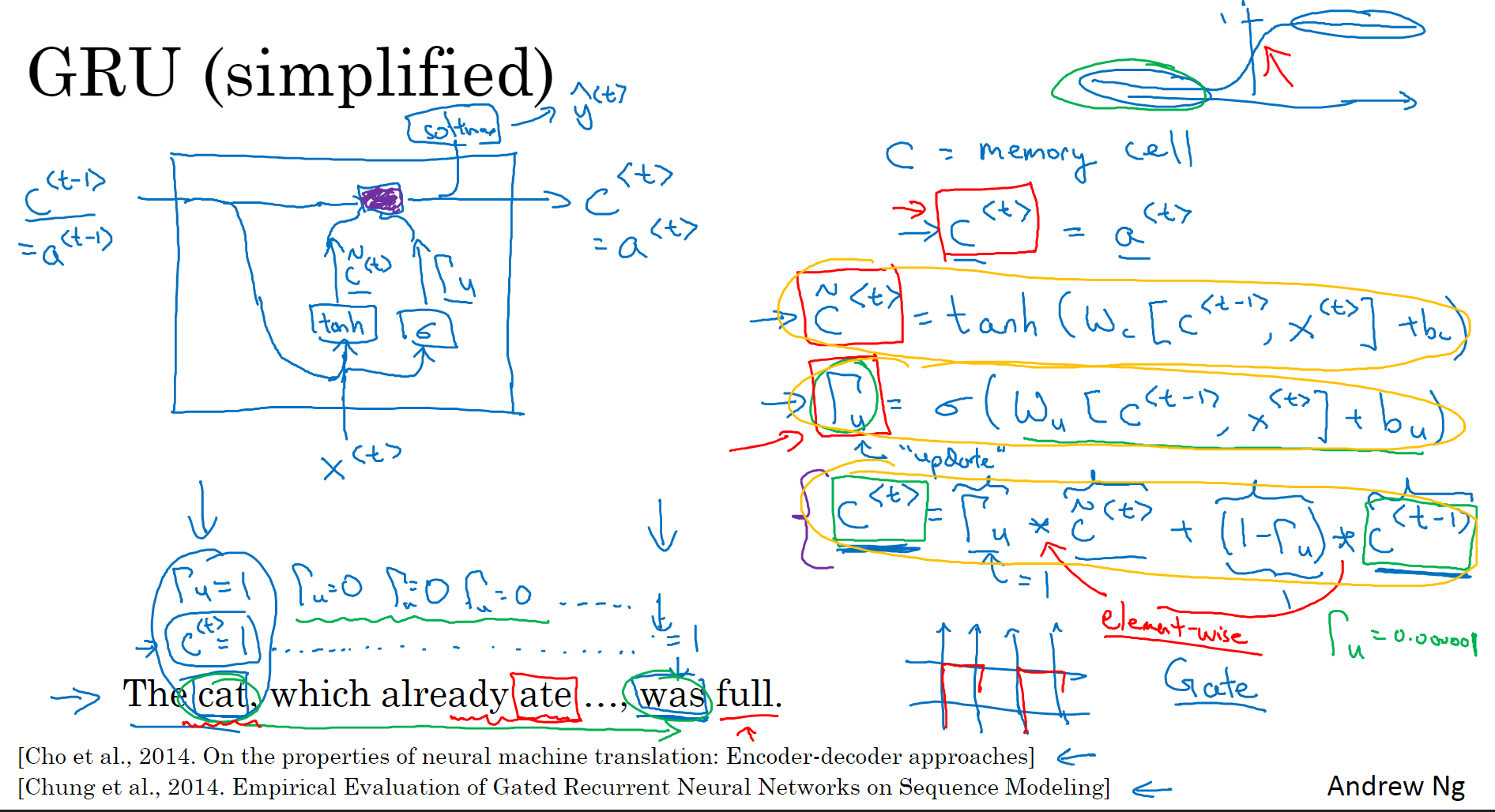
三个式子:
1、c-
2、Gate u(update):计算的是一个门限值,通过sigmod函数之后输出的是0-1之间的数,(方便理解的话就是0或者1,然后就类似一个们,从c-
3、c
因此,Γu能够保证RNN模型中跨度很大的依赖关系不受影响,消除梯度消失问题。
综合起来理解就是,有一个门限值(0-1)来控制前一时刻传递给后面的值的保留程度。
完整版GRU

也就是加入了一个相关门,计算前一层传递的影响程度。
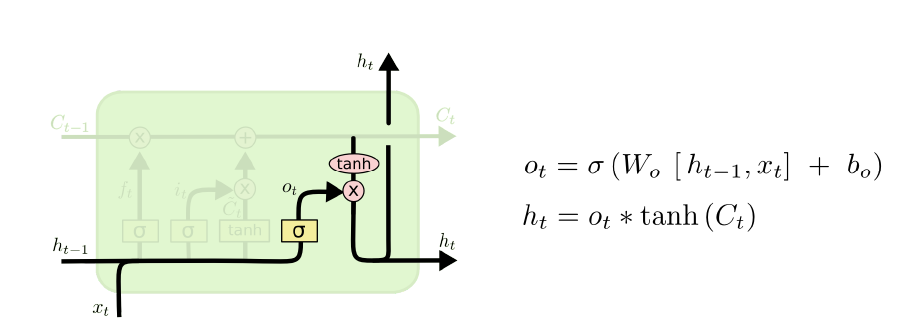
1.10 LSTM
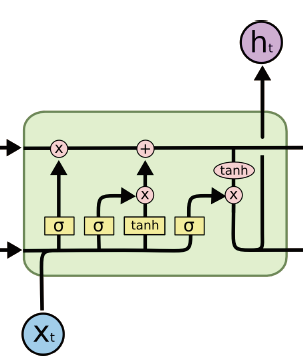
只有黄的是神经网络层(有参数),其他不是(运算)
流程
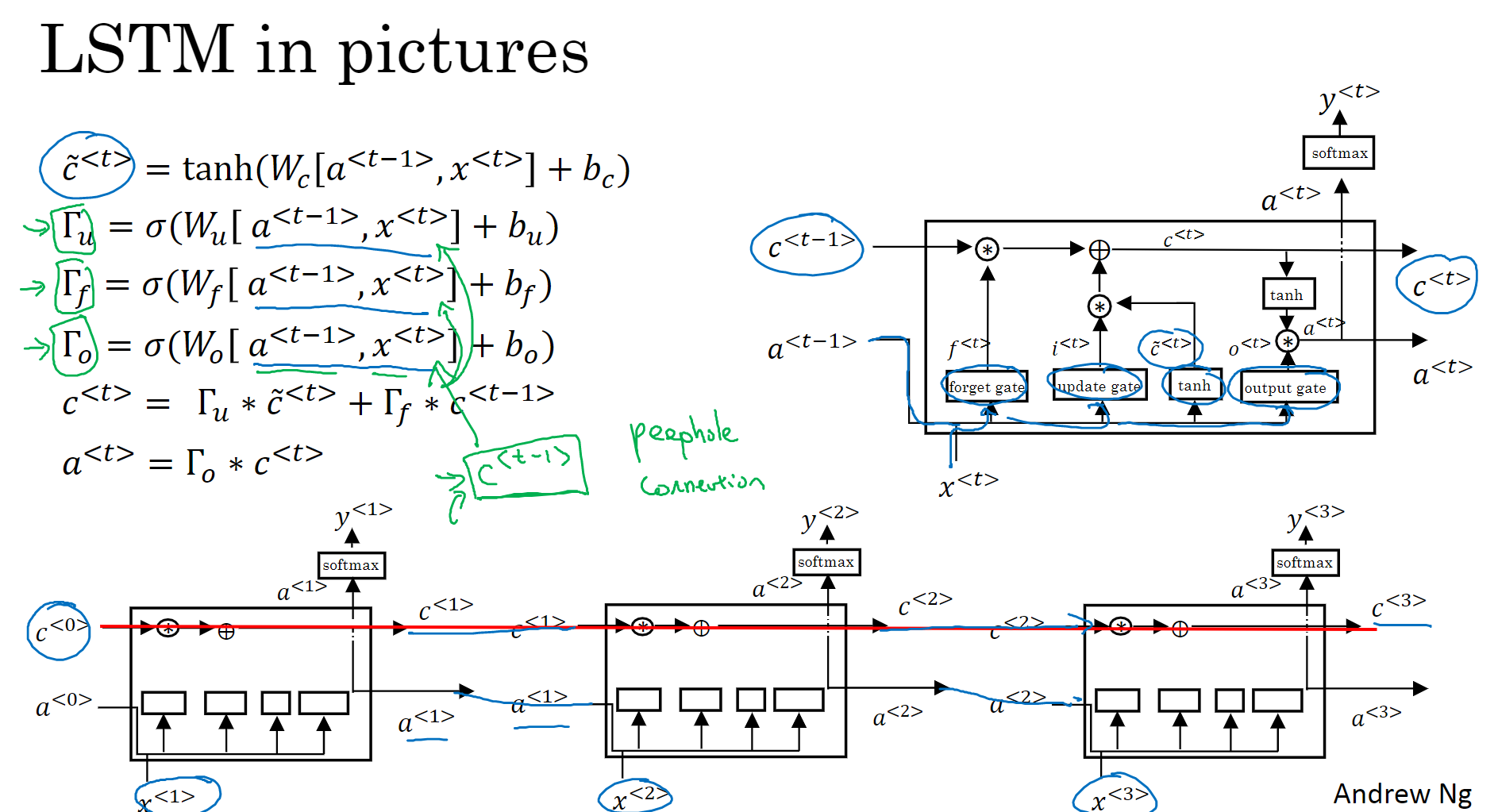
1、forget get:由前面的a和当前的x,线性计算后通过sigmoid,得到0-1之间的值,作用于前一个cell state,1表示保留,0表示丢弃。
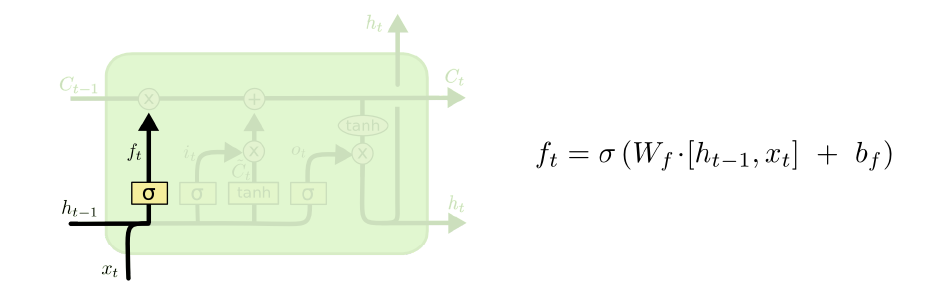
2、input gate(update gate):用于决定哪些信息将会被加入cell state中。决定哪些值将被更新
3、tenh层:构成的新候选词的向量生成器,可能被输入到cell state中。
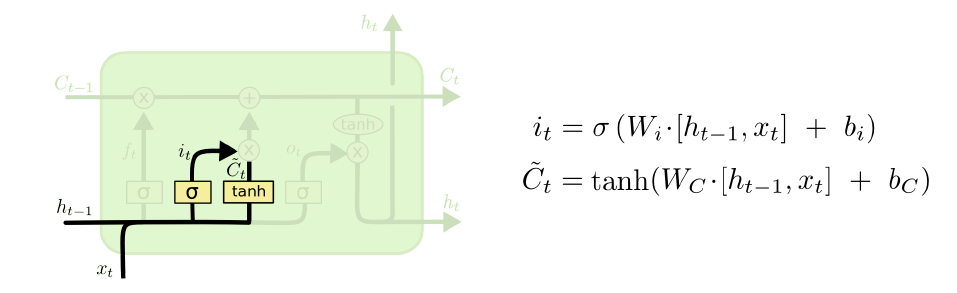
4、旧状态加新的候选信息,组成当前cellstate.
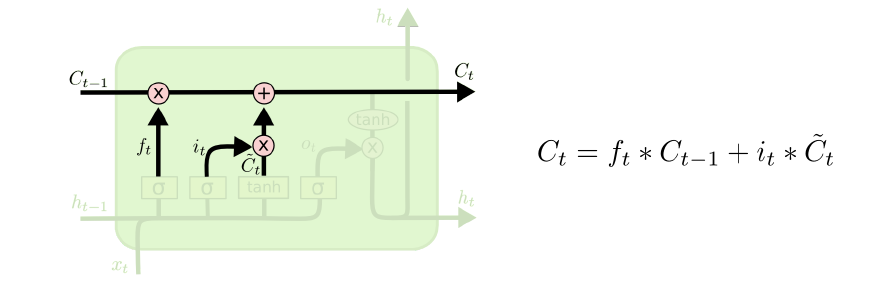
5、决定输出:输出是基于cell state,但先会有一个滤波的过程(output gate)。首先通过这些output gate(sigmoid层)决定哪些cell state输出,同时将cell state传到tanh层(-1——1),再乘以output gate 得到输出。
变体
1、加入 c
2、只算遗忘门,不算更新(1-f),
3、GRU

和GRU相比没有输入门了,统一由update门控制,但是有一个rate门,(感觉这样一综合其实和之前的两个门其实也区别不大了吧。)
然后输入也少了一个(应该也不算,只是把cell的值,直接当场a的值了)
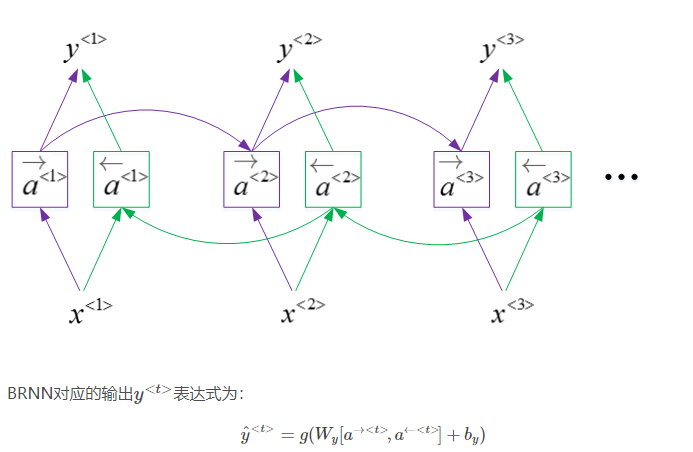
1.11 BRNN
BRNN能够同时对序列进行双向处理,性能大大提高。但是计算量较大,且在处理实时语音时,需要等到完整的一句话结束时才能进行分析。
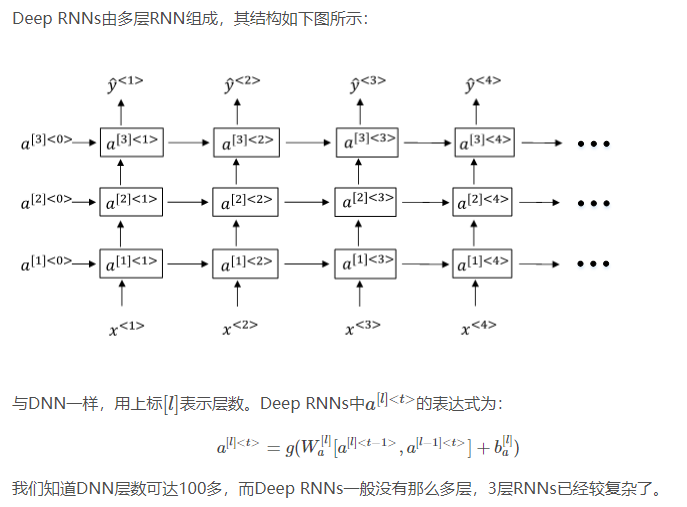
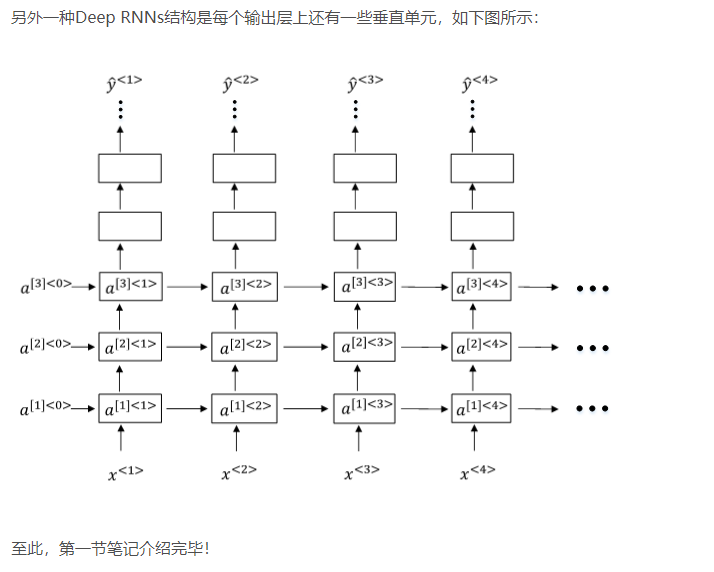
1.12 Deep RNNs