
《深度学习》 章三 结构化机器学习项目 第1节 机器学习(ML)策略(1)
章三 结构化机器学习项目 第1节 机器学习(ML)策略(1)
第1节 机器学习(ML)策略(1)
1.1 Why ML Strategy
当我们最初得到一个深度神经网络模型时,我们可能希望从很多方面来对它进行优化,例如:

1.2 正交化
通过每次只调试一个参数,保持其它参数不变,使模型某一性能改变是一种最常用的调参策略,也就是正交化方法。

换验证集,使用新的cost function来实现。概括来说,每一种“功能”对应不同的调节方法。而这些调节方法(旋钮)只会对应一个“功能”,是正交的。
顺便提一下,early stopping在模型功能调试中并不推荐使用。因为early stopping在提升验证集性能的同时降低了训练集的性能。也就是说early stopping同时影响两个“功能”,不具有独立性、正交性。
1.3 单一数字评估指标
查准率Precision:如果你的分类器(猫)认为该图片是猫,有一定的概率是正确的,这个概率就是查准率。
查全率Recall:在所有为猫的图片中,成功识别出多少。
不推荐使用这两个来判断模型优劣,需要一个结合二者的指标,也就是F1 score。

1.4 满足和优化指标
有时候,要把所有的性能指标都综合在一起,构成单值评价指标是比较困难的。解决办法是,我们可以把某些性能作为优化指标(Optimizing metic),寻求最优化值,越优越好;而某些性能作为满意指标(Satisficing metic),只要满足阈值就行了。
1.5 训练/开发/测试集划分
原则上应该尽量保证dev sets和test sets来源于同一分布且都反映了实际样本的情况。如果dev sets和test sets不来自同一分布,那么我们从dev sets上选择的“最佳”模型往往不能够在test sets上表现得很好。这就好比我们在dev sets上找到最接近一个靶的靶心的箭,但是我们test sets提供的靶心却远远偏离dev sets上的靶心,结果这支肯定无法射中test sets上的靶心位置。
1.6 开发集和测试集的大小
当样本数量不多(小于一万)的时候,通常将Train/dev/test sets的比例设为60%/20%/20%,在没有dev sets的情况下,Train/test sets的比例设为70%/30%。当样本数量很大(百万级别)的时候,通常将相应的比例设为98%/1%/1%或者99%/1%。
实际应用中,可能只有train/dev sets,而没有test sets。这种情况也是允许的,只要算法模型没有对dev sets过拟合。但是,条件允许的话,最好是有test sets,实现无偏估计。
1.7 什么时候该改变开发/测试集和指标
举个猫类识别的例子。初始的评价标准是错误率,算法A错误率为3%,算法B错误率为5%。显然,A更好一些。但是,实际使用时发现算法A会误识别一些图片当做是猫,但是B没有出现这种情况。从用户的角度来说,他们可能更倾向选择B模型,虽然B的错误率高一些。这时候,就需要改变之前的评价标准。例如增加其他图片的权重,增加其代价。
机器学习的两个过程
概括来说,机器学习可分为两个过程:
第一步是找靶心,第二步是通过训练,射中靶心。但是在训练的过程中可能会根据实际情况改变算法模型的评价标准,进行动态调整。
1.8 为什么是人的表现
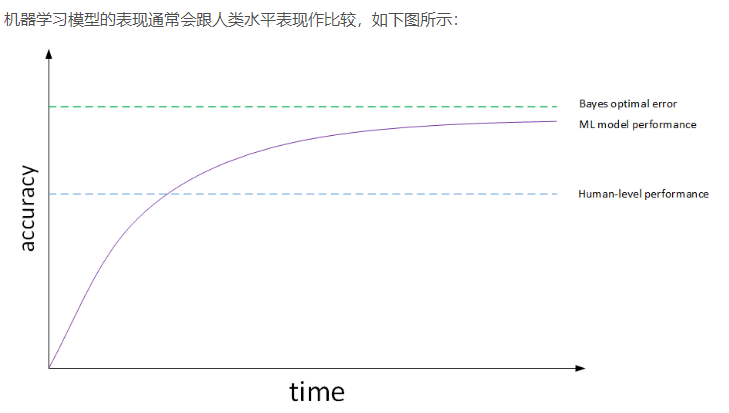

1.9 可避免偏差
实际应用中,要看human-level error,training error和dev error的相对值。例如猫类识别的例子中,如果human-level error为1%,training error为8%,dev error为10%。由于training error与human-level error相差7%,dev error与training error只相差2%,所以目标是尽量在训练过程中减小training error,即减小偏差bias。如果图片很模糊,肉眼也看不太清,human-level error提高到7.5%。这时,由于training error与human-level error只相差0.5%,dev error与training error只相差2%,所以目标是尽量在训练过程中减小dev error,即方差variance。这是相对而言的。实际应用中,我们一般会用human-level error代表bayes optimal error。
training error与human-level error之间的差值称为bias,也称作avoidable bias;把dev error与training error之间的差值称为variance。根据bias和variance值的相对大小,可以知道算法模型是否发生了欠拟合或者过拟合。增加训练时间 , 使用较大的网络结构 , 尝试更先进的优化算法(如Adam) , 或者修改网络结构(可能有效可能无效)可以减小偏差;采用更多的数据 , 其次使用正则化(Dropout, Batch Normzation , L1 , L2等等…) , 修改网络结构(可能有效可能无效 , 也可能同时减少方差和偏差)可以减小方差。
1.10 理解人的表现

1.11 超过人的表现

1.12 改善模型表现

