CompilerC0
来自NWPU课程《编译原理》试点班作业【2020年上】:编写一个C0文法的编译器。以递归下降子程序实现语法分析,输出AST,构建符号表,优化中间表达式,最终生成MIPS汇编代码。
项目地址:chen2511/CompilerC0: C0 文法编译器 Visual Studio2019 (github.com)
项目统计信息
总代码规模:4047行(不计空行),注释比例为21.7%
Visual Studio 2019, C++
- global.h:全局数据结构、全局变量
- scan.h:
- scan.cpp:词法分析实现
- parser.h:
- parser.cpp:语法分析:递归下降分析
- ast.h:
- ast.cpp:AST创建不同类型节点、输出AST
- symtab.h:
- symtab.cpp:符号表基本操作:插入、查找、初始化
- semantic.h:
- semantic.cpp:遍历AST,构建符号表、语义检查
使用说明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| int main(int argc, char* argv[])
{
processFileName(8);
sourceFile = fopen(sourcefilename.c_str(), "r");
AST_File = fopen(astfilename.c_str(), "w+");
|
main.cpp主函数需要调整,有两种方式:
1、调试项目时,使用第三行processFileName(8);代码,即处理input文件夹下8.c0文件
或者使用4-11行代码,或者命令行参数输入,处理源文件名字;
2、Visual Studio 采用Release x86 模式进行编译,生成可执行文件。
格式:执行文件 源文件
例如:.\CompilerC0-vs2019.exe .\Test12.c0
即可生成目标代码asm.txt
一、文法设计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| 1.<加法运算符> ::= +|-
2.<乘法运算符> ::= *|/
3.<关系运算符> ::= <|<=|>|>=|!=|==
4.<逻辑运算符> ::= && | '|| ' | !
5.<字母> ::= _|a|...|z|A|...|Z
6.<非零数字> ::= 1|...|9
7.<数字> ::= 0|<非零数字>
8.<无符号整数> ::= <非零数字>{<数字>}|0
9.<整数> ::= [+|-]<无符号整数>
10.<字符> ::= '<加法运算符>'|'<乘法运算符>'|'<字母>'|'<数字>'
11.<字符串> ::= "{十进制编码为32,33,35-126的ASCII字符}"
12.<标识符> ::= <字母>{<字母>|<数字>}
13.<程序> ::= [<常量说明>][<变量说明>]{<有返回值函数定义>|<无返回值函数定义>}<主函数>
14.<常量说明> ::= const<常量定义>;{ const<常量定义>;}
15.<常量定义> ::= int<标识符>=<整数>{,<标识符>=<整数>}| char<标识符>=<字符>{,<标识符>=<字符>}
16.<变量说明> ::= <变量定义>;{<变量定义>;}
17.<变量定义> ::= <类型标识符><标识符>[‘[’<无符号整数>‘]’] {,<标识符>[‘[’<无符号整数>‘]’]}
18.<类型标识符> ::= int | char
19.<有返回值函数定义> ::= <声明头部>‘(’<参数表>‘)’ ‘{’<复合语句>‘}’
20.<声明头部> ::= int<标识符> | char<标识符>
21.<无返回值函数定义> ::= void<标识符>‘(’<参数表>‘)’ ‘{’<复合语句>‘}’
22.<参数表> ::= <类型标识符><标识符>{,<类型标识符><标识符>}| <空>
23.<复合语句> ::= [<常量说明>][<变量说明>]<语句列>
24.<主函数> ::= void main ‘(’ ‘)’ ‘{’<复合语句>‘}’
25.<语句列> ::= {<语句>}
26.<语句> ::= <条件语句>|<循环语句>|‘{’<语句列>‘}’|<有返回值的函数调用语句>;|<无返回值的函数调用语句>;|<赋值语句>;|<读语句>;|<写语句>;|<空>;|<返回语句>;
27.<赋值语句> ::= <标识符>[‘[’<算术表达式>‘]’]=<算术表达式>
28.<条件语句> ::= if ‘(’<布尔表达式>‘)’<语句>[else<语句>]
29.<循环语句> ::= while ‘(’<布尔表达式>‘)’<语句>| for‘(’<赋值语句>;<布尔表达式>;<赋值语句>‘)’<语句>
30.<有返回值的函数调用语句> ::= <标识符>‘(’<值参数表>‘)’
31.<无返回值的函数调用语句> ::= <标识符>‘(’<值参数表>‘)’
32.<值参数表> ::= <算术表达式>{,<算术表达式>}|<空>
33.<读语句> ::= scanf ‘(’<标识符>{,<标识符>}‘)’
34.<写语句> ::= printf ‘(’<字符串>,<算术表达式>‘)’| printf ‘(’<字符串>‘)’| printf ‘(’<算术表达式>‘)’
35.<返回语句> ::= return[‘(’<算术表达式>‘)’]
36.<算术表达式> ::= [+|-]<项>{<加法运算符><项>}
37.<项> ::= <因子>{<乘法运算符><因子>}
38.<因子> ::= <标识符>|<标识符>‘[’<算术表达式>‘]’|<无符号整数>|<字符>|<有返回值函数调用语句>|‘(’<算术表达式>‘)’
39.<布尔表达式> ::= <布尔项> { ‘||’ <布尔项> }
40.<布尔项> ::= <布因子>{ && <布因子> }
41.<布因子> ::= false | true | ! <布因子> | ‘(‘<布尔表达式>’)’ | <条件因子> [<条件运算符> <条件因子>]
42.<条件因子> ::= <标识符>[‘[’<算术表达式>‘]’]| <无符号整数> | <字符> | <有返回值函数调用语句>
|
二、词法分析
摘要
词法分析作用是将字符流的源代码归纳成单词流。通过状态机出几种类型的词:
- 标识符、保留字(保留字先归类到标识符)
- 无符号整数
- 特殊符号(包括运算符、括号等等)
- 字符、字符串
正常的分析过程:
文法-正则表达式-NFA-DFA-DFA最小化-编程实现(如果文法设计的好,简单,中间几步可以简略)
状态机代码实现一般有两种:
- 隐藏状态:如果状态少,可以通过代码的选择和循环结构控制状态。
- 双重case(本文使用):第一重判断当前状态,第二重根据当前字符执行不同代码
注意的问题有:
- 读入缓冲:不直接操作文件指针,易于回溯与错误定位
- 保留字识别:先识别为标识符
- 带符号数处理:除了常量定义位置,表达式中都是无符号整数,带符号数用
0-num处理
正则表达式
标识符:[_a-zA-Z][_a-zA-Z0-9]*
三种类型:下划线、小写字母和大写字母,非数字开头
无符号整数:[1-9][0-9]*|0
一位整数0-9、非0开头的多位无符号整数
特殊符号:
1
2
3
4
| + - * /
&& '||' !
< <= > >= != ==
= : , ; [ ] { } ( )
|
字符:'[<加法运算符>|<乘法运算符>|<字母>|<数字>]'
字符串:"{十进制编码为32,33,35-126的ASCII字符}"
NFA 不确定有限自动机
Nondeterministic Finite Automata
有限自动机是一个抽象的概念,可以用两种 直观的方式—状态转换图和状态转换矩阵来 表示。有限表示状态有限。

状态转换图是一个有向图,NFA中的每个状态对应转换图中的一个节点;
NFA中的每个f函数对应转换图中的一条有向边,该有向边从si 节点出发,进入sj节点,字符ch(或ε)是边上的标记;
NFA的初态是状态转换图中没有前驱的节点;
节点一般用一个圆圈表示,
终态节点用一个双圈表示。
举例:

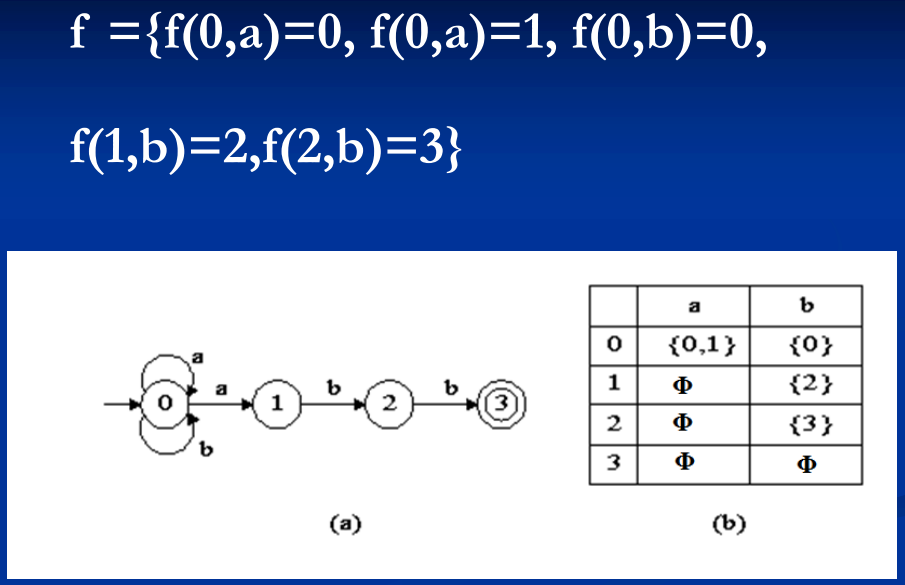
NFA的特点是它的不确定性,即在当前状态下,对同一个字符ch,可能有多于一个的下一状态转移。
DFA 确定的有限自动机
DFA是NFA的一个特例,其中:
- 没有状态具有ε状态转移(ε-transition),即状 态转换图中没有标记ε的边;
- 对每一个状态s和每一个符号a,最多有一 个下一状态。
特性:对一个状态遇到一个字符,状态转移是唯一确定的
定理:NFA必有DFA与之对应。
DFA 最小化
在确定DFA之后,还可以进一步简化状态数。
是唯一的。
PPT里面有简化方法和例子。
Ch3
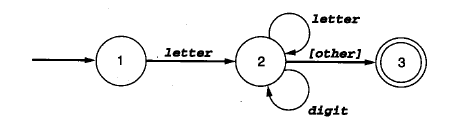
词法分析编程实现
由于我们文法设计没有很复杂而且将不同token转化成正则表达式也不复杂,所以没有NFA-DFA最小化等步骤。
可以直接画出状态转换图,再编程实现。
数据结构
1 Token
1
2
3
4
| typedef struct{
TokenType opType;
char * value;
}Token;
|
2 TokenType
枚举类型
1
2
3
4
5
6
7
8
9
10
11
12
13
| typedef enum {
//关键字:
CHAR, CONST, ELSE, FALSE, FOR, //0-4
IF, INT, MAIN, PRINTF, RETURN, //5-9
SCANF, TRUE, VOID, WHILE, //10-13
NUM, IDEN, LETTER, STRING, //14-17:数字、标识符、字符、字符串
PLUS, MINU, MULT, DIV, //18-21:+ - * /
AND, OR, NOT, //22-24:&& || !
LSS, LEQ, GRE, GEQ, NEQ, EQL, //25-30关系运算符: < <= > >= != ==
ASSIGN, COLON, COMMA, SEMICOLON, //31-34: = : , ;
LBRACE, RBRACE, LBRACKET, RBRACKET, //35-38:{ } [ ]
LPARENTHES, RPARENTHES, //39-40:( )
}TokenType;
|
3 保留字表
1
2
3
4
5
6
| const char* reservedWords[] = {
"case", "char", "const", "default", "else",
"false", "for", "if", "int", "main",
"printf", "return", "scanf", "switch", "true",
"void", "while"
};
|
4 状态
1
2
3
| typedef enum {
STATE_START, STATE_NUM, STATE_ID, STATE_CHAR, STATE_STRING, STATE_DONE
}StateType;
|
用Token表示每一个词(词法分析的一次处理结果),里面包括两部分,tokentype表示类型;用char *表示一些有值的类型(数字、字符串)。
DFA编程思想
来自Louden书《编译原理与实践》的思路
1 通过代码位置表示隐含状态
if判断不同符号进入不同分支;循环表示不断读入当前状态的循环字符。
注意advance the input表示读入一个符号

2 双重case
实际用的就是这个
专门设置一个变量表示当前状态,循环判断非end状态,内部使用双重case语句,第一重测试状态,第二重测试当前字符(进行状态转换)。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
|
void getNextToken() {
string tmpstr;
char ch;
StateType state = STATE_START;
g_lexBegin = g_forward;
while (STATE_DONE != state) {
ch = getNextChar();
if (EOF == ch) {
g_token.opType = END;
return;
}
switch (state)
{
case STATE_START: {
if (' ' == ch || '\\t' == ch || '\\n' == ch) {
}
else if (isdigit(ch)) {
if ('0' == ch) {
state = STATE_DONE;
tmpstr += ch;
g_token.opType = TokenType::NUM;
}
else {
state = STATE_NUM;
tmpstr += ch;
}
}
else if (isalpha(ch) || '_' == ch) {
state = STATE_ID;
tmpstr += ch;
}
else if ('\\'' == ch) { //字符
state = STATE_CHAR;
}
else if ('"' == ch) { //字符串
state = STATE_STRING;
}
else { //一个或两个字符就到终态
state = STATE_DONE;
tmpstr += ch;
switch (ch) {
case '+': // +
g_token.opType = TokenType::PLUS;
break;
case '-': // -
g_token.opType = TokenType::MINU;
break;
case '*': // *
g_token.opType = TokenType::MULT;
break;
case '/': // /
g_token.opType = TokenType::DIV;
break;
case '&': // &&
ch = getNextChar();
if ('&' == ch) {
g_token.opType = TokenType::AND;
tmpstr += ch;
}
else {
cout << "lex error: &&\\n";
}
break;
case '|': //||
ch = getNextChar();
if ('|' == ch) {
g_token.opType = TokenType::OR;
tmpstr += ch;
}
else {
cout << "lex error: ||\\n";
}
break;
case '!': // ! !=
ch = getNextChar();
if ('=' == ch) {
g_token.opType = TokenType::NEQ;
tmpstr += ch;
}
else {
backSpace();
g_token.opType = TokenType::NOT;
}
break;
case '<': // < <=
ch = getNextChar();
if ('=' == ch) {
g_token.opType = TokenType::LEQ;
tmpstr += ch;
}
else {
backSpace();
g_token.opType = TokenType::LSS;
}
break;
case '>': // > >=
ch = getNextChar();
if ('=' == ch) {
g_token.opType = TokenType::GEQ;
tmpstr += ch;
}
else {
backSpace();
g_token.opType = TokenType::GRE;
}
break;
case '=': // = ==
ch = getNextChar();
if ('=' == ch) {
g_token.opType = TokenType::EQL;
tmpstr += ch;
}
else {
backSpace();
g_token.opType = TokenType::ASSIGN;
}
break;
case ',':
g_token.opType = TokenType::COMMA;
break;
case ';':
g_token.opType = TokenType::SEMICOLON;
break;
case '{':
g_token.opType = TokenType::LBRACE;
break;
case '}':
g_token.opType = TokenType::RBRACE;
break;
case '[':
g_token.opType = TokenType::LBRACKET;
break;
case ']':
g_token.opType = TokenType::RBRACKET;
break;
case '(':
g_token.opType = TokenType::LPARENTHES;
break;
case ')':
g_token.opType = TokenType::RPARENTHES;
break;
}
}
break;
}
case STATE_CHAR:
if (isdigit(ch) || isalpha(ch) || '+' == ch || '-' == ch || '*' == ch || '/' == ch) {
tmpstr += ch;
}
else {
cout << "lex error:illegal character\\n";
}
ch = getNextChar();
state = STATE_DONE;
// 有一处bug,下面这句忘记加了。。。
g_token.opType = TokenType::LETTER;
if ('\\'' != ch) {
backSpace();
cout << "lex error:not '\\n";
}
break;
case STATE_ID:
if (isdigit(ch) || isalpha(ch) || '_' == ch) {
tmpstr += ch;
}
else {
state = STATE_DONE;
backSpace();
g_token.opType = TokenType::IDEN;
}
break;
case STATE_NUM:
if (isdigit(ch)) {
tmpstr += ch;
}
else {
state = STATE_DONE;
backSpace();
g_token.opType = TokenType::NUM;
}
break;
case STATE_STRING:
if ('"' == ch) {
state = STATE_DONE;
g_token.opType = TokenType::STRING;
}
else if (32 <= ch && 126 >= ch) {
tmpstr += ch;
}
else {
cout << "lex error: illegal character in string\\n";
}
break;
default:
break;
}
|
3 转换表
代码简单,易维护,但是表可能很大,不推荐
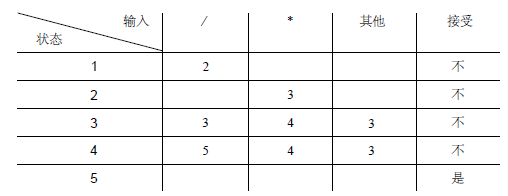

注意问题(重点)
1、读入缓冲
缓冲的意思是,不是直接通过指针操作文件,而是,先读进来一个数组的数据,在数组中操作;
便于定位错误的位置;简便
然后有单缓冲和双缓冲的区别;
而北航是多了一个backup数组;
louden书中的例子,也是有一个缓冲数组lineBuf
2、保留字的识别
将保留字也先看做标识符,再识别保留字
匹配保留字表,字典序查询(线性低效)
3、带符号数处理
+1+1
最长字串原则:if32i 这种字符串时,我们将对整个字符串进行匹配,而不是匹配到if就返回类型IF。简单说是往最长的结果匹配。
但我们理解的:第二个 +1和第一个+1是有区别的,如果词法阶段就有带符号数,那么按照最长字符串原则会得到两个token,两个+1
但实际我们想要的可能是:+1,+,1
通过总结带符号数的规律,发现:其中要么带符号数要么在开头,要么有括号;其他情况数字都是无符号的
所以,总结来说,我们可以把这个符号当做表达式来处理,前面补一个0;
4、冲突解决与错误处理(略)
三、语法分析
摘要
语法分析的作用是单词归纳成句子的序列;需要生成抽象语法树(左孩子右兄弟)。
到生成AST这里算前端,前端处理不同语言,后端统一处理AST
工作流程分为两个部分:
1、先理论设计AST(设计分成四个部分程序、语句、算术表达式、布尔表达式);程序实现构造AST(树的结构是什么样,存储哪些信息)
2、对于语法(文法)上,计划采用递归下降分析法(手写实现简单),文法最好满足LL(1)文法(大致理解是看到下一个token就知道用哪一个推导式)
需要大量的设计和验证(这里废了很多功夫)
在实现时,最好将文法转化为EBNF范式便于实现;
难点:
函数定义和变量定义的回溯保留
算术表达式的设计
布尔表达式的设计
二义性的解决(以if-else为例:就近原则;布尔表达式中的算术表达式无法使用括号嵌套)
语法分析是做什么?(通俗理解)
词法是字符序列转成单词序列;(看一个单词是否合法)
语法分析是单词转成句子的序列(看一个句子是否合法)。需要生成抽象语法树
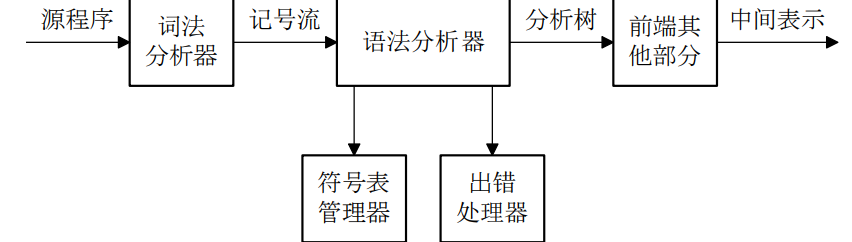
LL分析法,LR分析法
LL(k)文法:通过从左往右超前查看k个字符决定采用哪一个产生式。(分支预测)
名字中第一个L表示从左往右扫描字符串,;第二个L表示最左推导,对于每一个产生式都要从左往右开始分析即可。
提取左公因式的方法,转化为LL(k)的文法。
递归子程序(递归下降法)
好用程序实现,对语言所用的文法有一些限制(MS官方的C#编译器就是用这种方法)
抽象语法树 AST 的理论设计
特点:
不依赖于具体的文法(语法分析方式):无论是自上而下或自下而上的语法分析,都要求在语法分析时候,构造出相同的语法树,这样可以给编译器后端提 供了清晰,统一的接口。- 不依赖于语言的细节:gcc可以编译多种语言,
前端处理不同语言,后端统一处理AST
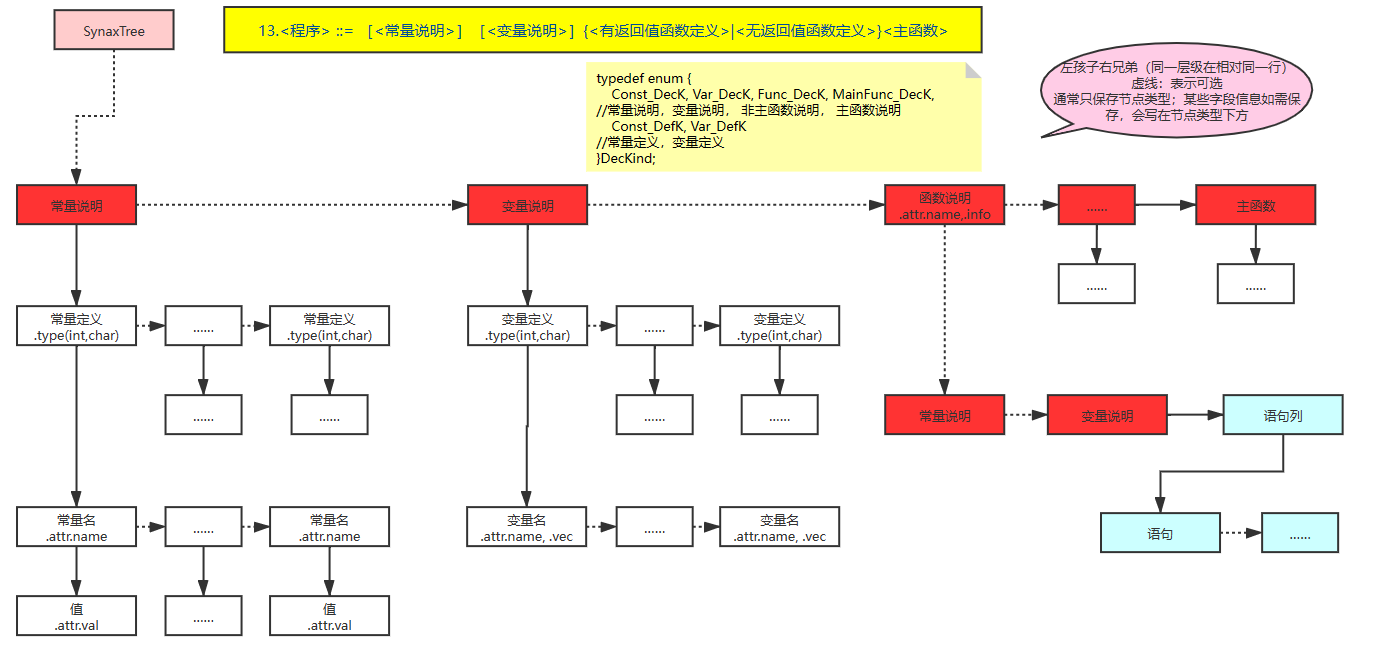
我定义的:(左孩子右兄弟),有四块内容
1、整体结构:
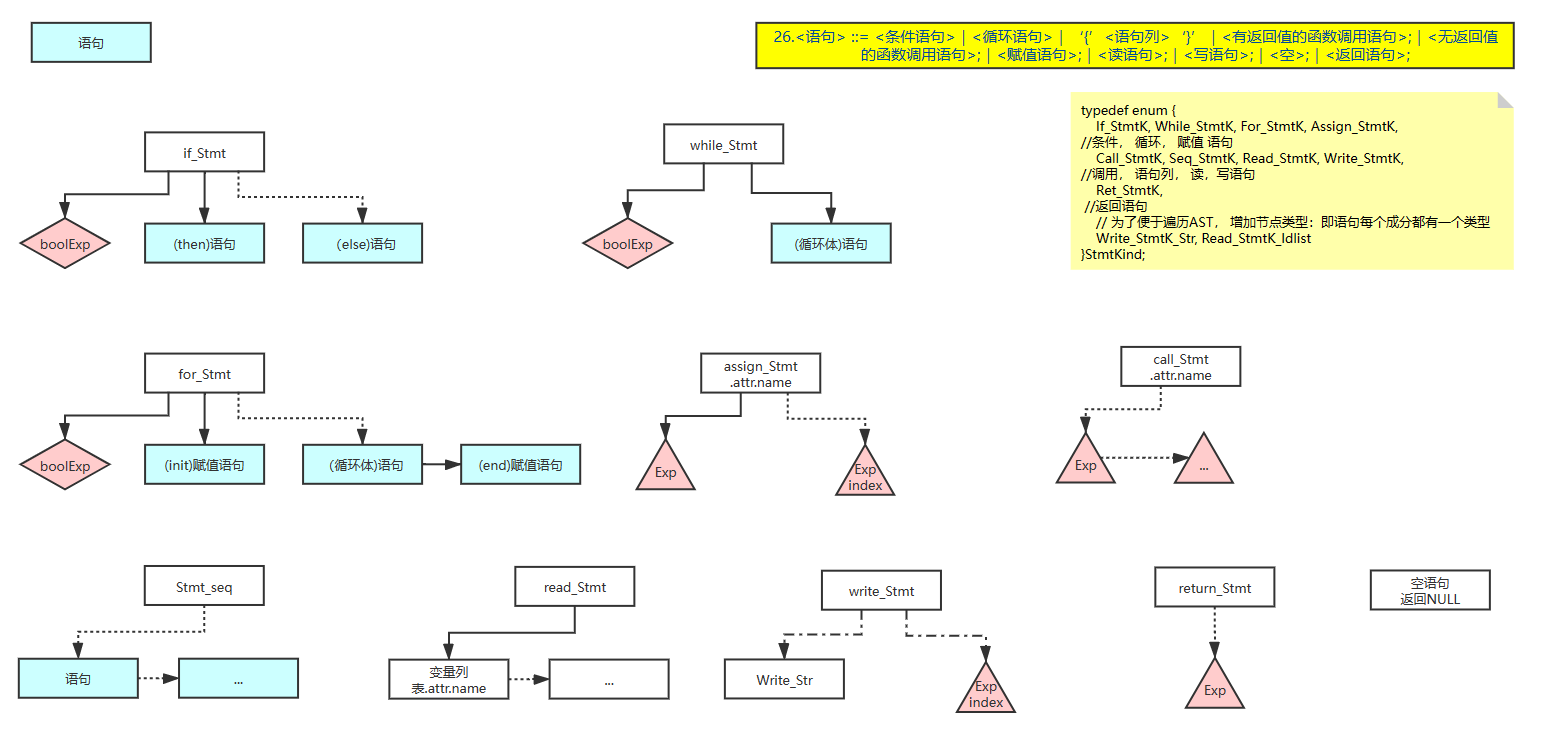
2、语句
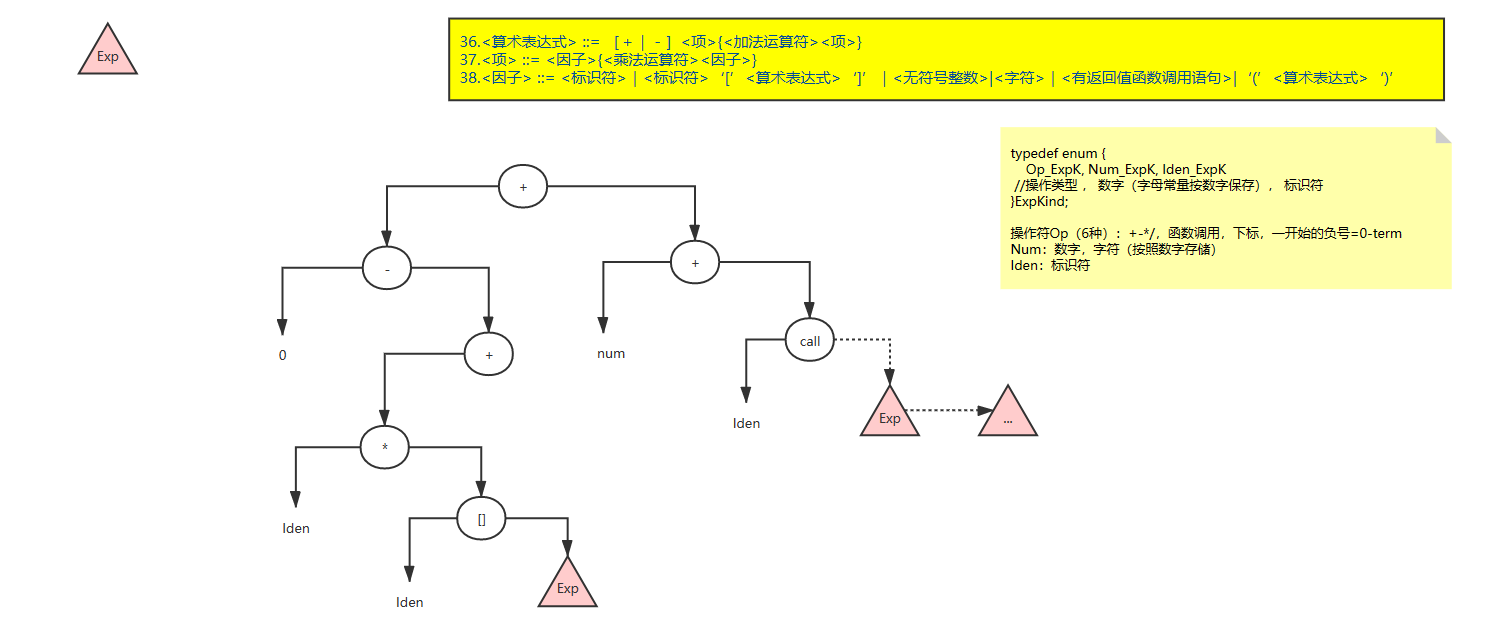
3、算术表达式:(算是较为完整)
支持加减乘除、括号,数组下标引用、有返回值函数调用;
对象可以是字面量和变量的字符和无符号整数类型
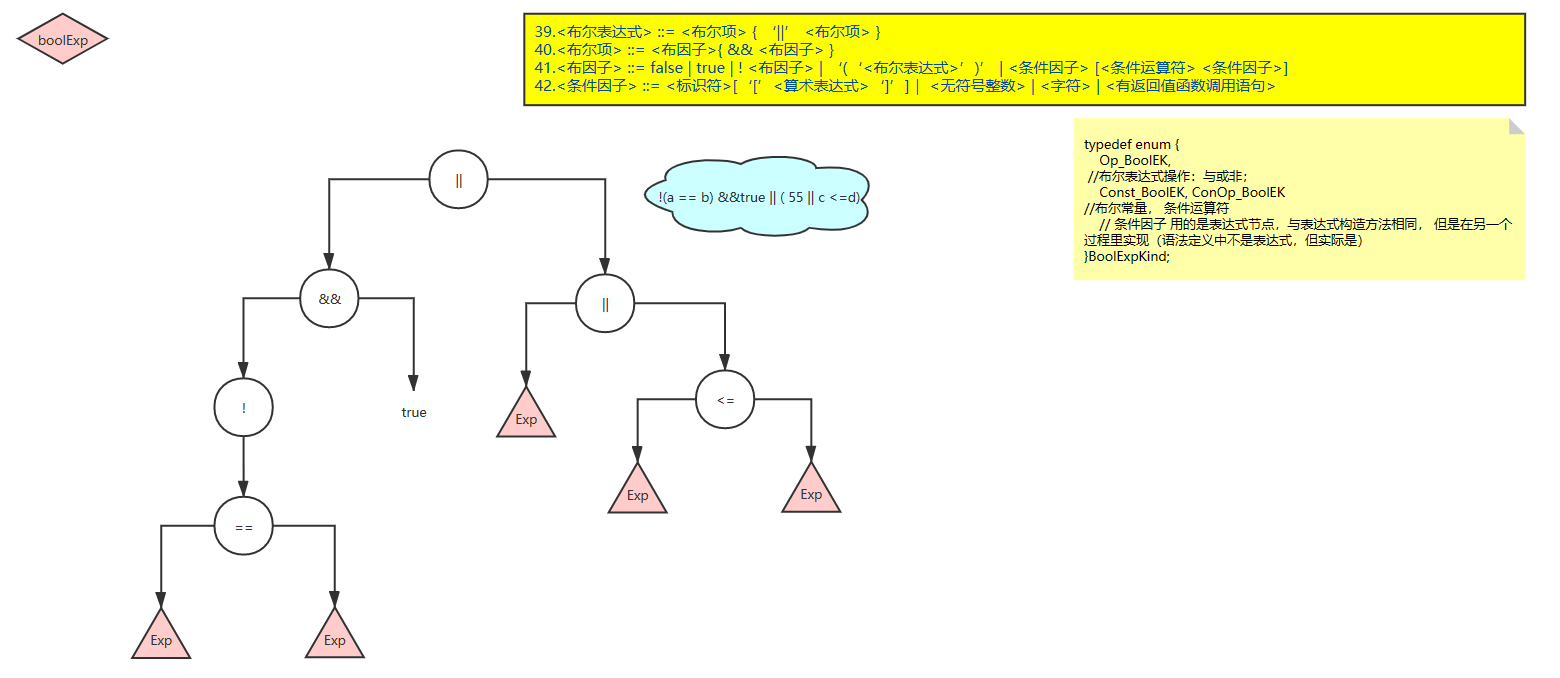
4、布尔表达式:
支持与或非、括号、条件运算符(大于、小于等的比较运算)
LL(1)文法的理论定义
FIRST集合
对于推导式:First(S)就是S能推导出来的第一个终结符

FOLLOW集合
可紧跟在非终结符A后的所有终结符之集
D背后紧跟着R,R的第一个是d

LL(1)文法
判断文法为LL(1)文法的条件:
(1)文法不含左递归
(2)根据产生式的首字符进行判断(也就是通过第一个字符就能判断使用哪个产生式)

编程:递归向下分析法(使用递归子程序法)
设计好了文法,如何编程实现?
将文法表示成EBNF范式的形式更好实现!
对于文法的每个非终结符,根据其各候选式的结构,为其建立一个递归的子程序(函数),用于识别该非终结符所表示的语法范畴.

match:以其实参与当前正扫描的符号进行匹配,若成功则返回1,否则返回0;
advance:读下一单词的函数
term:与非终结符T相对应的子程序.
1、AST的程序表示
理解了理论定义后,代码方面会简单很多。
1、左孩子右兄弟,孩子可能不止一个
2、大致用哪些数据结构存储了哪些信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
typedef struct TreeNode {
struct TreeNode* child[MAX_TREENODE_CHILD_NUM];
struct TreeNode* sibling;
NodeKind nodekind;
union {
DecKind dec;
StmtKind stmt;
ExpKind exp;
BoolExpKind bexp;
}kind;
union {
TokenType op;
int val;
unsigned char cval;
char* name;
bool bval;
char* str;
}attr;
int vec;
Type type;
FuncInfo* pfinfo;
char* place;
int TC, FC;
int lineno;
bool error;
}TreeNode;
|
2、ENBF范式代码实现
必须出现直接匹配;
可选用if判断
多次用循环判断
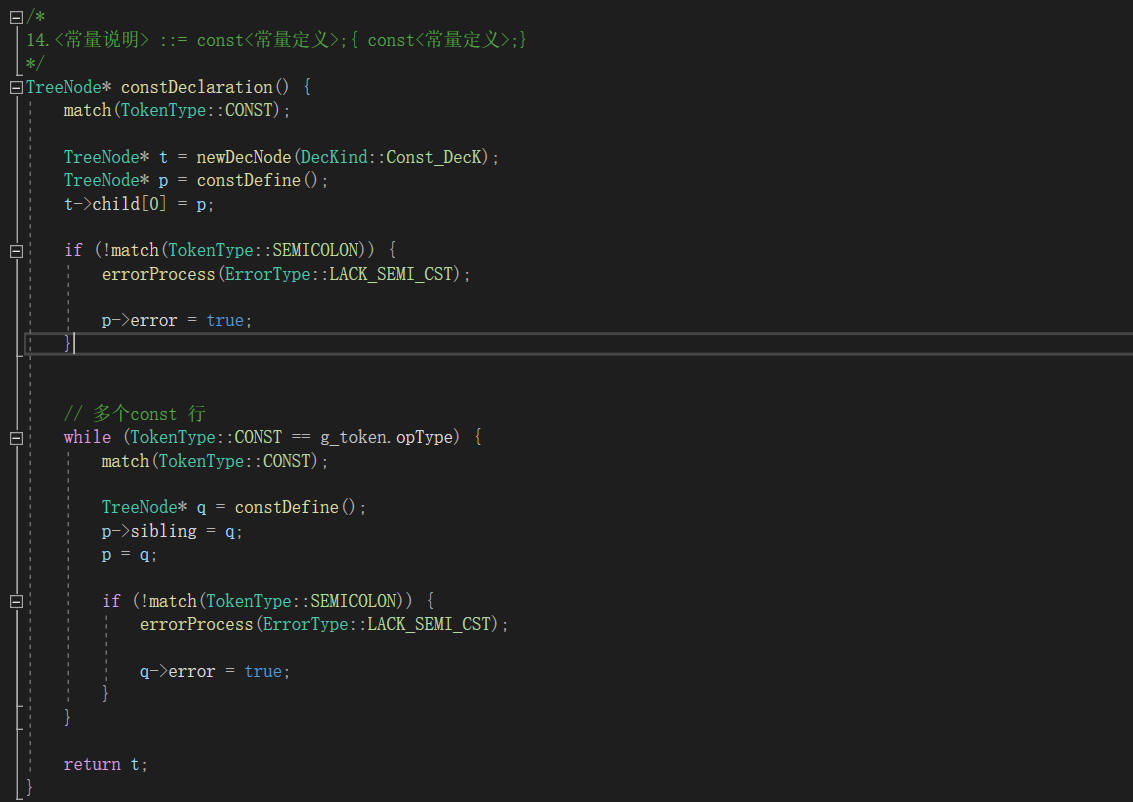
注意问题(这里涉及文法设计)
1、避免回溯(提高效率)
解决:改造文法
有些无法避免,也没必要。(可以部分地方多读几个,类似LL(k))
如函数定义时
我的程序:
1)判断变量定义还是函数,需要提前看两个token,看是不是括号
2)判断是不是main函数,需要提前一个token
2、二义性
规定原则:优先匹配近的
因为算术表达式设计得齐全;在布尔表达式部分内部的算术表达式就不支持括号了;(这是一个缺陷)
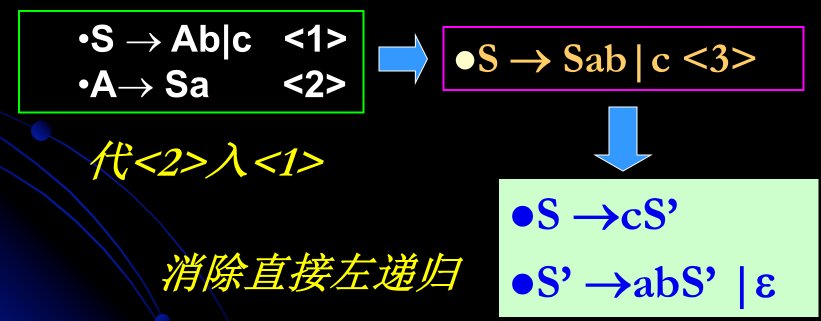
3、消除左递归(避免死循环)(略)
包含直接左递归和间接左递归两种
解决:改造文法或者EBNF范式

代入消除间接左递归:
4、提取公因子(略)

四、语义分析
摘要
功能是语句的语义是否有明确的含义。(比如语法检查每个token类型是否匹配即可;这里需要检查标识符的类型是否正确)
工作分为两个部分,构造符号表和语义检查。(一次遍历)
1、定义符号表(多级hash链表);符号表是语义检查的基础,所以在常量、变量、函数定义部分先构建符号表(往符号表中添加符号)
其实符号表在背后的生成四元式(插入临时变量)和生成汇编代码都有用(在符号表中保存内存的地址和寄存器位置)
2、语义检查是在表达式、和各种语句中检查标识符是否有明确的含义。(查找符号表)
类型检查和定义检查是主要内容
即用到标识符时类型是否正确;标识符是否定义
难点:
- 符号表的结构:多级hash链表
- 同名标识符就近原则
一般的编译器:词法分析、语法分析、语义分析是同时进行的,一遍
我的:生成AST之后,再遍历AST,构建符号表,进行语义分析(事实上技术上的难度没什么差别,都很简单,做的事情基本一样)
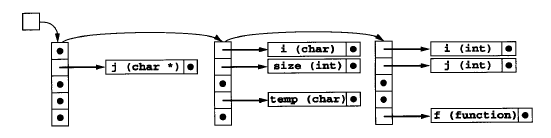
符号表
符号表的结构选择:分级hash链表(名字作为键);分级表示不同作用域(全局或者函数内部);
因此可以实现同名标识符(选择作用域最近)。不允许使用同名函数、标识符和函数同名。
程序实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| #define SYMBOL_TABLE_SIZE 211
typedef enum IDType {
Const_ID, Var_ID, Para_ID, Func_ID
}IDType;
typedef struct Symbol {
char* name;
IDType type;
Type valueType;
int value;
int adress;
int vec;
FuncInfo* pfinfo;
struct Symbol* next;
}Symbol, * SymbolList;
typedef struct SymTab {
SymTab* next;
char* fname;
SymbolList hashTable[SYMBOL_TABLE_SIZE];
}SymTab;
|
一些字段的说明:
1、标识符名字;
2、标识符有四种:常量、变量、函数参数、函数
3、标识符的类型:空、整形、字符、错误
4、内存地址:这个很关键,有两个变量来维护;一个是全局地址;一个是函数局部地址(函数栈帧相对地址)
5、数组大小
6、函数定义的信息:返回值,参数个数,各个参数
7、作为链表节点,指向下一个节点
以递归地方式遍历AST,构造符号表。
每个函数一张表:第一张表示全局表(保存全局变量和函数名);后面的是函数表,新的函数始终保持在第二张表
相关操作:
- 初始化:新增一张表,输入为表名
- 增:向对应符号表插入一个符号(符号可以是变量、常量、函数参数、函数、标识符);还可以插入临时变量(计算表达式时使用)
- 查:先查当前函数表(在第二张),再查全局表(第一张)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
SymTab* initSimpleSymTable(char* name);
bool insert_SymTab(bool isGlobal, char* name, IDType type, Type valuetype, int value, int vec = -1, FuncInfo* p = NULL);
void insertTempVar2SymTab(char* name)
Symbol* lookUp_SymTab(char* name);
|
语义检查
主要工作是对标识符的类型检查和定义检查(操作类型是否匹配、前面是否定义了函数或标识符,传参的个数和类型是否对得上)
还是递归遍历AST
要检查的地方:
1、算术表达式中:
- 常量:跳过
- 标识符:未定义使用;是数组不进行下标运算
- 函数调用:函数未定义使用,不是有返回值调用,参数个是否匹配
- 数组引用:未定义;非数组进行下标运算;
需考虑运算符两侧操作数是否合法,比如int和bool类型相加,由于只有char和int,暂不考虑
表达式都看作是int型运算,只有语句中需要时根据左值类型进行转换
2、布尔表达式中:
3、语句中:
- 赋值语句:标识符未定义、检查是否变量(常量不能赋值)、不是数组进行下标运算、是数组不进行下标运算
- 函数调用语句:函数未定义、是否是函数、参数是否匹配(个数和类型)
(函数传参有可能传表达式,所以需要验证)
- 读语句:标识符未定义、不能是常量
- 写语句:占用符与表达式不匹配(是否有%d,%c)
五、中间代码(四元式)生成
摘要
功能:将AST(四种类型)转化成四元式(一个操作符,最多三个操作数);便于代码优化
难点:
- 大部分操作较为简单
- 布尔操作符比较复杂:1、if和while语句的程序块放置位置。2、有短路现象、需要拉链回填(需要提前结束,还要设置各种跳转地址、标签)
举例:如何理解布尔表达式的短路部分:考虑if语句里面的判断是一个或的表达式。
这时候根据then、else、后续代码有分三段代码块;这三段都对应一个label(跳转地址)
为了能够提前结束,还要拉链。将整个布尔表达式的真假和或两边的表达式的真假联系起来。
也就是在表达式中得要拉链的结果,在if-else语句中回填标签
设计四元式
设计四元式一定要设计成上下文无关的。包括几种类型:
- 计算:加减乘除、下标引用
- 定义:常量、变量、函数
- 语句:函数调用、输入输出
- 布尔:跳转、标签
| op |
var1 |
var2 |
var3 |
| +-*/ |
id/num |
id/num |
result |
| callret |
id(函数名) |
|
id(ret) |
| getarray |
id(数组名) |
id/num(index) |
id |
| jop |
id |
id |
label |
| j |
|
|
label |
| jnz |
id/num |
|
label |
| const |
int/char |
val |
name |
| int/char |
|
|
name |
| intarray |
size |
|
name |
| chararray |
size |
|
name |
| Func |
int/char/void |
|
name |
| para |
int/char |
|
name |
| Main |
|
|
|
| setarray |
id/num |
index |
name |
| assign |
id/num |
|
name |
| lab |
|
|
label |
| call |
name |
|
|
| vpara |
|
|
id/num |
| scanf |
|
|
name |
| print |
str_index |
|
|
| print |
|
id/num |
int/char |
| ret |
|
|
id/num |
| ret |
|
|
|
| endf |
|
|
算术表达式的四元式生成
需要存储中间临时变量:加减乘除、查数组、函数调用都要将结果存到临时变量里在代码中是tree->place属性,如$1
布尔表达式的四元式生成
以布尔表达式在if语句中为例:

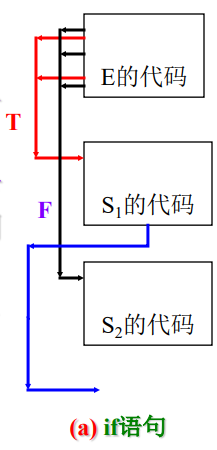
布尔表达式E可能有提前结束,为真,执行S1代码,之后跳过S2;为假跳到执行S2代码,再继续执行。
代码实现是:先构造布尔表达式的代码,再生成3个代码标签,放在S1、2的前后。
代码顺序是:BoolExp-label_true-S1-label-false-S2-continue_label
注意当确定了label的名字之后,需要拉链和回填
拉链回传通过语法树的TC、FC变量实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| IR_BoolExp(tree->child[0]);
char* truelabel = newlabel();
char* falselabel = newlabel();
char* conlabel = newlabel();
gen("lab", newempty(), newempty(), truelabel);
backPatch(tree->child[0]->TC, truelabel);
IR_Analyze(tree->child[1]);
gen("j", newempty(), newempty(), conlabel);
gen("lab", newempty(), newempty(), falselabel);
backPatch(tree->child[0]->FC, falselabel);
IR_Analyze(tree->child[2]);
gen("lab", newempty(), newempty(), conlabel);
|
bool Exp 里面有 4 种节点: 布尔op、布尔常量、关系op、表达式
1、当前tree节点是算术表达式:
详解:先生成算术表达式的代码,生成代码(jnz, tree->place, '', zero) ,第二条是j类型;再由TC和FC辅助走真假两条路;
也就是说jnz(序号为NXQ)里面的跳转地址应为真链(满足条件);j(序号为NXQ)为假链,不满足条件
1
2
3
4
5
6
7
| if (tree->nodekind == NodeKind::ExpK) {
IR_Exp(tree);
tree->TC = NXQ;
tree->FC = NXQ + 1;
gen("jnz", tree->place, newempty(), zero);
gen("j", newempty(), newempty(), zero);
}
|
2、布尔op(大于、等于等等)
要先生成两个EXp的代码;将临时变量的结果保存到两个孩子的place属性里
再设置两个分支布尔op和j分支,对应这一个满足条件,一个不满足条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| if (tree->kind.bexp == BoolExpKind::ConOp_BoolEK) {
IR_Exp(tree->child[0]);
IR_Exp(tree->child[1]);
tree->TC = NXQ;
tree->FC = NXQ + 1;
switch (tree->attr.op)
{
case TokenType::LSS:
gen("<", tree->child[0]->place, tree->child[1]->place, zero);
break;
case TokenType::LEQ:
gen("<=", tree->child[0]->place, tree->child[1]->place, zero);
break;
case TokenType::GRE:
gen(">", tree->child[0]->place, tree->child[1]->place, zero);
break;
case TokenType::GEQ:
gen(">=", tree->child[0]->place, tree->child[1]->place, zero);
break;
case TokenType::EQL:
gen("==", tree->child[0]->place, tree->child[1]->place, zero);
break;
case TokenType::NEQ:
gen("!=", tree->child[0]->place, tree->child[1]->place, zero);
break;
default:
break;
}
gen("j", newempty(), newempty(), zero);
}
|
3、布尔常量
与单独的表达式相同
4、与或非
非就是把自己的链和孩子的链反过来即可。
1
2
3
4
5
| if (TokenType::NOT == tree->attr.op) {
IR_BoolExp(tree->child[0]);
tree->FC = tree->child[0]->TC;
tree->TC = tree->child[0]->FC;
}
|
或要注意:或有两个部分(孩子);根据常见的理解:第一个表达式为真,那么第二个就不用测试了
代码理解:先生成左孩子;接着立马生成一个标签放在右孩子代码的前面,用于左孩子为假时,立马跳转到这里开始判断;也就是说这里要回填为左孩子的假链;
接着继续拉链左孩子的真链为总体的真链;
再生成右孩子的表达式;这时候才得到整个或语句的假链的位置;
要将右孩子的真链和左孩子的真链合并才得到整个语句的真链
1
2
3
4
5
6
7
8
9
10
11
| IR_BoolExp(tree->child[0]);
char* ll = newlabel();
gen("lab", newempty(), newempty(), ll);
backPatch(tree->child[0]->FC, ll);
tree->TC = tree->child[0]->TC;
IR_BoolExp(tree->child[1]);
tree->FC = tree->child[1]->FC;
tree->TC = merge(tree->child[0]->TC, tree->child[1]->TC);
|
六、目标代码生成-MIPS
摘要
功能:将中间代码转换成真正能够运行的MIPS汇编代码。
主要解决:(剩余的工作大多是翻译的工作)
1、内存分配:指定数据和代码的位置
2、寄存器分配思路:除固定寄存器外,使用FIFO原则使用10个临时寄存器
3、栈帧的创建与销毁:与函数开始与结束;函数调用与返回语句四个过程有关。
函数开始和结束需要维护栈帧结构(保存和还原栈帧寄存器和返回地址、开辟空间保存变量);函数调用需要保存寄存器现场;返回语句负责保存返回值到相应寄存器。
难点与出bug的地方:
- 保证寄存器和内存的
一致性,寄存器保存现场的时机:不是函数调用时,而是每一个代码块(有分支的位置)()
内存分配方案
将IR转换成真正能够运行的汇编代码,首先要确定如何将数据和运行的代码放入内存,放在哪些区域。
过程为:先处理全局变量;在处理函数体(函数体首先要确认栈帧的结构,返回地址、参数等,再处理函数内容)
用到的几个部分:
- .data段:存放全局变量,字符串常量
- .text段:存放代码
- stack:运行时使用,保存栈帧(地址从高到低)

寄存器分配思路
全部的寄存器:
| 寄存器 |
别名 |
用途 |
| $0 |
$zero |
常量0(constant value 0) |
| $1 |
$at |
保留给汇编器(Reserved for assembler) |
| $2-$3 |
$v0-$v1 |
函数调用返回值(values for results and expression evaluation) |
| $4-$7 |
$a0-$a3 |
函数调用参数(arguments) |
| $8-$15 |
$t0-$t7 |
暂时的(或随便用的) |
| $16-$23 |
$s0-$s7 |
保存的(或如果用,需要SAVE/RESTORE的)(saved) |
| $24-$25 |
$t8-$t9 |
暂时的(或随便用的) |
| $26~$27 |
$k0~$k1 |
保留供中断/陷阱处理程序使用 |
| $28 |
$gp |
全局指针(Global Pointer) |
| $29 |
$sp |
堆栈指针(Stack Pointer) |
| $30 |
$fp |
帧指针(Frame Pointer) |
| $31 |
$ra |
返回地址(return address) |
一般用的:
$fp:栈顶(高地址)$sp:栈底(低)$ra:存储的是返回地址,即函数结束时会运行jr $ra,即回到函数调用者的下一条指令;函数调用时,需要将下一条指令地址放入这个寄存器$v0:如果函数有返回值,会将结果放入该寄存器$a0-$a3:参数寄存器。其实本项目没有用,都放入内存了。$t0-$t9:10个寄存器是使用频率很高的
下面主要讲这10个寄存器的使用思路:考虑到其实这相当于内存的cache,主要解决一致性的问题。
如果我们要操作一个数、变量、数组的元素;那么首先去检查是否在寄存器堆(该状态保存在符号表);如果在则直接使用;不在需要从内存载入。这时又需要看寄存器堆是否有空余的,如果有,则直接载入;没有则根据FIFO原则将原有值放回内存再使用新寄存器。
主要函数:getRegIndex每次输入变量名就可以直接获得该变量存储的寄存器序号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
int getRegIndex(char* varname) {
if (isdigit(varname[0]) || varname[0] == '-') {
return getAnEmptyReg(varname, NULL);
}
Symbol* sb = lookUp_SymTab(varname, isGlobal);
if (!sb) {
printf("unexpect error: cannot find symbol\n");
exit(-1);
}
if (sb->isreg) {
isInReg = true;
return checkRegInfoList(varname);
}
else {
isInReg = false;
return getAnEmptyReg(varname, sb);
}
}
|
两个辅助函数:1、checkRegInfoList检查变量在哪一个寄存器。2、getAnEmptyReg获得一个可以用的寄存器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
int checkRegInfoList(char* varname) {
std::list<RegInfo>::iterator iter = regInfoList.begin();
for (; iter != regInfoList.end(); ++iter) {
if (!strcmp((*iter).varname, varname)) {
INFO("剩余寄存器:%d,已在寄存器:true,变量名:%s,寄存器序号:%d\n", s_emptyRegNum, varname, std::distance(regInfoList.begin(),iter));
break;
}
}
if (iter == regInfoList.end()) {
printf("unpected error in checkRegInfoList()\n");
}
RegInfo nn = (*iter);
regInfoList.push_back(nn);
regInfoList.erase(iter);
return nn.regindex;
}
int getAnEmptyReg(char* varname, Symbol* sb) {
if (s_emptyRegNum > 0) {
if (sb) {
sb->isreg = true;
}
int index = 10 - s_emptyRegNum;
s_emptyRegNum--;
RegInfo nn = { index, varname };
regInfoList.push_back(nn);
INFO("剩余寄存器:%d,变量名:%s,寄存器序号:%d\n", s_emptyRegNum, varname, index);
return index;
}
else {
RegInfo nn = regInfoList.front();
regInfoList.pop_front();
if (isdigit(nn.varname[0]) || '-' == nn.varname[0]) {
}
else {
Symbol* sb_pop = lookUp_SymTab(nn.varname, p_isGlobal);
sb_pop->isreg = false;
if (sb_pop->vec >= 0) {
}
else {
if (p_isGlobal) {
fprintf(ASM_FILE, "\tsw\t\t$t%d, $%s\n",
nn.regindex,
nn.varname
);
}
else {
fprintf(ASM_FILE, "\tsw\t\t$t%d, -%d($fp)\n",
nn.regindex,
sb_pop->adress
);
}
}
}
if (sb) {
sb->isreg = true;
}
RegInfo ttt = { nn.regindex, varname };
regInfoList.push_back(ttt);
INFO("剩余寄存器:%d,old变量名:%s,变量名:%s,寄存器序号:%d\n", s_emptyRegNum, nn.varname, varname, nn.regindex);
return nn.regindex;
}
}
|
难点-Bug:什么时候要保存现场?
初始思路:按照函数分配的(跳转函数才会保存现场,清空寄存器)
后来在测试到快速排序的时候,由于各种跳转,导致寄存器有问题;不是正确的运行结果;
如,之前要判断的某个循环变量分配到1号寄存器,但是循环内部变量较多,1号寄存器被移除,存储新的变量;这时跳转回去判断,寄存器里面就不是原来的变量了。
正确的方法:按照基本块来分配
首先是基本块划分:
- 程序的第一个四元式
- 转向语句的目标四元式(即j,jnz,jop的目标)
- 条件跳转jop的下一条(由于四元式生成过程中下一条总是 j)
具体方法:j的时候清空,遇到label的时候清空。(对应的就是跳转语句的目标和条件跳转的下一句)。
也就if-else处;while循环结束
栈帧处理过程:
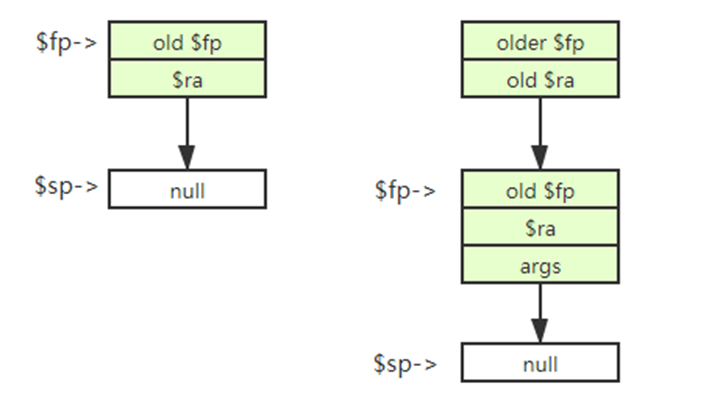
1、函数开始:
(前提:函数调用者需要压入返回地址,保存寄存器的现场)
1、函数开始,先设置寄存器堆状态为可用;
2、sw $fp, ($sp)保存栈基址寄存器的值到栈变址寄存器(这个位置是低地址,空)
3、move $fp, $sp栈基址变成了栈变址的值(也就是返回的时候弹出新的基址对应的内存地址的值就是原来那个栈帧的基址的值)
4、subi $sp, $sp, 8变址-=8;(要存两个元素,原来的栈基址和函数返回地址;用于函数返回时栈帧和指令计数器的还原)
5、sw $ra, 4($sp)压入返回地址(这个返回地址是函数调用者的下一条指令地址)
6、压入参数、局部变量和临时变量(算术表达式的中间产生的变量)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| s_emptyRegNum = 10;
regInfoList.clear();
fprintf(ASM_FILE, "\tsw\t\t$fp, ($sp)\n");
fprintf(ASM_FILE, "\tmove\t$fp, $sp\n");
fprintf(ASM_FILE, "\tsubi\t$sp, $sp, 8\n");
fprintf(ASM_FILE, "\tsw\t\t$ra, 4($sp)\n");
matchParaType();
ignoreVarDef();
insertTempVar(cur_4var);
fprintf(ASM_FILE, "\tsubi\t$sp, $sp, %d\n", g_symtab->next->varsize - 8);
|
2、函数结束:
1、打标签:便于函数中间的返回语句直接跳转
2、保证内存和寄存器的一致性:由于寄存器相当于内存的cache,要将一些全局变量写会内存(函数的全局变量可以抛弃)
3、lw $ra, -4($fp)恢复返回地址寄存器
4、恢复函数调用者的栈帧:move $sp, $fp ,lw $fp, ($fp)
5、函数返回,跳转到寄存器ra的地址的指令:jr $ra
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
fprintf(ASM_FILE, "ret_%s:\n", s_funcName);
saveReg();
fprintf(ASM_FILE, "\tlw\t\t$ra, -4($fp)\n");
fprintf(ASM_FILE, "\tmove\t$sp, $fp\n");
fprintf(ASM_FILE, "\tlw\t\t$fp, ($fp)\n");
fprintf(ASM_FILE, "\tjr\t\t$ra\n");
cur_4var++;
|
3、函数调用语句:
保存寄存器的值到内存(保存现场和一致性,子函数返回后还会使用这些值)
jal function跳转到某个地址的同时将下一条指令的地址保存在寄存器$ra中
1
2
3
4
5
6
| void call2asm()
{
saveReg();
fprintf(ASM_FILE, "\tjal\t\t%s\n", quadvarlist[cur_4var].var1);
}
|
4、return语句
- 1、控制返回值:需要做类型校验和截断处理
move $v0, $t_
- 2、跳转到返回处理部分:
j ret_function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| void ret2asm()
{
if (quadvarlist[cur_4var].var3[0] == ' ') {
if (Type::T_VOID != s_funcRetType) {
printf("return type error ,id: %s\n", quadvarlist[cur_4var].var3);
}
}
else {
int r3 = getRegIndex(quadvarlist[cur_4var].var3);
mem2reg(quadvarlist[cur_4var].var3, r3);
fprintf(ASM_FILE, "\tmove\t$v0, $t%d\n", r3);
if (isdigit(quadvarlist[cur_4var].var3[0])) {
if (Type::T_VOID == s_funcRetType) {
printf("return type error ,id: %s\n", quadvarlist[cur_4var].var3);
}
else if (Type::T_CHAR == s_funcRetType) {
fprintf(ASM_FILE, "\tandi\t$v0, $v0, 0xff\n");
}
else {
}
}
else {
Type real_ret_type = lookUp_SymTab(quadvarlist[cur_4var].var3)->valueType;
if (Type::T_VOID == s_funcRetType) {
printf("return type error ,id: %s\n", quadvarlist[cur_4var].var3);
}
else if (Type::T_CHAR == s_funcRetType) {
fprintf(ASM_FILE, "\tandi\t$v0, $v0, 0xff\n");
}
else {
}
}
}
fprintf(ASM_FILE, "\tj\t\tret_%s\n", s_funcName);
}
|
其他语句(系统调用):
完成输入输出的功能。
难点:
保证一致性
七、优化
1、划分基本块
划分规则:
- 程序的第一个四元式
- 转向语句的目标四元式(即j,jnz,jop的目标)
- 条件跳转jop的下一条(由于四元式生成过程中下一条总是 j)
由于本人程序在生成IR过程中的特殊性,条件跳转的下一条语句总是j,跳转的目标总是label
所以基本块划分方法可以简化为 遇到j和label就是基本块入口
下面所说的优化基本是在基本块内的优化,可以叫做线性窥孔优化。
2、寄存器优化
可见目标代码生成部分。原本的寄存器分配可以是用完立即保存到内存,而不是使用10个。
3、强度削弱
强度削弱: 乘法和除法改为移位。首先需要判断当前操作是否有立即数,如果有,进一步判断是否是2的次方,如果是,就可以转换为移位操作。
1、求模运算改成按位与(未实现,因为文法不包括求模)
2、非算术运算的削弱,尽量使用寄存器(和寄存器优化有关)
3、
4、常量合并
算地慢不如算地快,算地快不如不计算
常量合并:常量计算改为赋值。也就是将 + - * / 转化为 赋值。
常数传播(未实现,文法限制):在程序运行时,某段程序中的一些变量之值保持不变。直接替换成值的引用
5、删除公共子表达式
算法思路[1]:
- (当前四元式序号为A)从A开始扫描基本块,由上向下找出有相同的op(对应DAG图中的父节点),var1(对应DAG图中的左子节点),var2(对应DAG图中的右子节点)且var3为临时变量的四元式B
- 从B向下继续扫描四元式,寻找所有与B具有相同var的四元式C1,C2,…;
- 将Ci的var置为var3;
- 删除B,置B为 NULL
八、错误处理
8.1、错误识别
1
2
3
4
5
6
7
8
9
10
11
12
13
|
static bool match(TokenType expectToken) {
if (expectToken == g_token.opType) {
getNextToken();
return true;
}
else {
g_errorNum++;
printf("match error in line %d :\t\texpect Token %d, but %d value: %s \n", g_lineNumber, expectToken, g_token.opType, g_token.value);
return false;
}
}
|
8.2、跳读到可以正确分析的位置
直到识别到某些token才停止;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| typedef enum {
LACK_SEMI_CST,
LACK_TYPE_CST,
LACK_ID_CST,
LACK_ASSIGN_CST,
LACK_XXX_VARDEF,
LACK_TYPE_FUN,
LACK_IDEN_FUN,
LACK_KUOHAO_FUN,
SENTENCE_ERROR
}ErrorType;
|
大致思想:
常量定义、变量定义、函数定义:跳过当前定义
语句:跳过当前语句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| switch (e)
{
case ErrorType::LACK_SEMI_CST:
case ErrorType::LACK_TYPE_CST:
case ErrorType::LACK_ID_CST:
case ErrorType::LACK_ASSIGN_CST: {
while (g_token.opType != TokenType::CONST && g_token.opType != TokenType::INT && g_token.opType != TokenType::CHAR
&& g_token.opType != TokenType::VOID && g_token.opType != TokenType::IF
&& g_token.opType != TokenType::WHILE && g_token.opType != TokenType::FOR
&& g_token.opType != TokenType::IDEN && g_token.opType != TokenType::RETURN
&& g_token.opType != TokenType::SCANF && g_token.opType != TokenType::PRINTF
&& g_token.opType != TokenType::LBRACE && g_token.opType != TokenType::RBRACE
)
{
if (g_token.opType == TokenType::END)
{
exit(0);
}
getNextToken();
}
break;
}
case ErrorType::LACK_XXX_VARDEF: {
while (g_token.opType != TokenType::INT && g_token.opType != TokenType::CHAR
&& g_token.opType != TokenType::VOID && g_token.opType != TokenType::IF
&& g_token.opType != TokenType::WHILE && g_token.opType != TokenType::FOR
&& g_token.opType != TokenType::IDEN && g_token.opType != TokenType::RETURN
&& g_token.opType != TokenType::SCANF && g_token.opType != TokenType::PRINTF
&& g_token.opType != TokenType::LBRACE && g_token.opType != TokenType::RBRACE
)
{
if (g_token.opType == TokenType::END)
{
exit(0);
}
getNextToken();
}
break;
}
case ErrorType::LACK_TYPE_FUN:
case ErrorType::LACK_IDEN_FUN:
case ErrorType::LACK_KUOHAO_FUN: {
while (g_token.opType != TokenType::INT && g_token.opType != TokenType::CHAR
&& g_token.opType != TokenType::VOID
)
{
if (g_token.opType == TokenType::END)
{
exit(0);
}
getNextToken();
}
break;
}
case ErrorType::SENTENCE_ERROR: {
while (g_token.opType != TokenType::IF
&& g_token.opType != TokenType::WHILE && g_token.opType != TokenType::FOR
&& g_token.opType != TokenType::IDEN && g_token.opType != TokenType::RETURN
&& g_token.opType != TokenType::SCANF && g_token.opType != TokenType::PRINTF
&& g_token.opType != TokenType::RBRACE
)
{
if (g_token.opType == TokenType::END)
{
exit(0);
}
getNextToken();
}
break;
}
|
8.3 语法树错误屏蔽
语法树标识错误,语义分析时跳过。
九、 bug修复
1、asm生成阶段:scanf语句
bug:多次读取同名变量时,由于scanf是直接写入内存,但或许之前使用过这个变量,并且已经调入寄存器;查表的时候会显示在寄存器堆中,这样就会读取就值;
发现于 Test11.c0;多次输入x,发现后面使用的x的值始终不变
(old,会带来新问题,可用寄存器数目不断减少)处理:从寄存器堆中移除此变量,且不用写回内存;故只需更新符号表状态、寄存器映射队列、可用寄存器数目
(new)处理:如果在寄存器,则更新寄存器数据即可,其他不变
2、寄存器分配策略错误
之前的寄存器分配是按照函数分配的(跳转函数才会清空寄存器);后来在测试到快速排序的时候,由于各种跳转,导致寄存器有问题;不是正确的运行结果;如,之前要判断的某个循环变量分配到1号寄存器,但是循环内部变量较多,1号寄存器被移除,存储新的变量;这时跳转回去判断,寄存器里面就不是原来的变量了。
正确的方法:按照基本块来分配
首先是基本块划分:
- 程序的第一个四元式
- 转向语句的目标四元式(即j,jnz,jop的目标)
- 条件跳转jop的下一条(由于四元式生成过程中下一条总是 j)
划分完基本块后,在每个基本块结束时清空即可(或是下一基本块开始时,清空上一基本块;本质就是基本块开始时,全部寄存器是空的);这样就不会出现各种跳转就不会出现寄存器出错的问题。
我采用的具体方法:j的时候清空,遇到label的时候清空。(对应的就是跳转语句的目标和条件跳转的下一句)。所以,该方法时正确的。程序的结果也是正确的。
十、参考
[1] 实现一个C++实现的拓展C0文法MIPS交叉编译器https://www.cnblogs.com/sciencefans/articles/4235139.html
[2] 编译原理哈工大慕课与PPT
https://www.icourse163.org/learn/HIT-1002123007?tid=1206830204#/learn/content
[3] 编译原理 第3版 蒋立源 2005
[4] 现代编译原理C语言描述tif虎书
[5] 编译原理西工大PPT
[6] MIPS汇编入门
https://www.cnblogs.com/thoupin/p/4018455.html
[7] MIPS汇编快速入门
https://blog.csdn.net/u012837895/article/details/79855896
[8] SYSCALL functions available in MARS
https://blog.csdn.net/sdreamq/article/details/50776393
[9] Simple语言的定义(LL1文法)
https://wenku.baidu.com/view/0fc831e8998fcc22bcd10de9
[10] 《编译原理》控制流语句 if 和 while 语句的翻译
https://www.cnblogs.com/xpwi/p/11072234.html


